Avalanche with ContinualAI
이번 PyTorch Ecosystem Day 2021의 Poster 세션에서 소개된 것들이 정말 많았습니다. 그 중 Continual Learning에 관련된 라이브러리로 Avalanche가 있었는데, 마침 회사에서 이 논문을 정리할 니즈가 생겨서 이 글에 정리해봅니다.
이 논문은 실로 논문스럽게 정의 내리고 분석한 부분이 있는 반면, 대부분이 프레임워크를 소개한 글에 가깝습니다. 논문의 형태를 띨 뿐 사실 논문보다 코드를 보는 게 이해가 더 쉬운 느낌이어서, 굳이 논문의 흐름을 완전히 따라가지는 않고 제가 이해한 흐름대로 설명합니다.
Abstract
고정되지 않고 계속 생기고 흐르는 데이터들을 학습시키는 것(Continual Learning, 이하 ‘CL’)은 ML 필드에서 오랫동안 있었던 논의였고 Challenging한 문제였습니다. 최근에 딥러닝 커뮤니티에서 Continual Learning에 대한 관심이 높아지는 것을 볼 수 있었는데, 문제는 이게 구현하기가 너무 어렵다는 것입니다.
특성 상 여러 Setting과 Condition들이 있을 수 있는데 이걸 반복적으로 포팅하고 재구현하는 것은 어렵고 소모적입니다. 그래서 저자들은 Avalache를 만들었고, CL 알고리즘에 대한 빠른 Prototyping과 Training, 그리고 재현 가능한 Evaluation을 제공해주고 싶다고 합니다.
Design Principle
저자들은 Design Principle을 정의하기에 앞서, 그 기초로 다음의 내용을 언급합니다. 이 내용이 만족되는 것이 Researcher들과 Practitioner들을 돕는 길이라고 생각한다고 합니다.
- 적은 코드, 빠른 프로토타이핑, 감소된 오류
- 향상된 재현성 (Repoducibility)
- 모듈성(Modularity)과 재사용성(Reusability) 선호
- 코드의 효율성(Efficiency), 확장성(Scalability), 휴대성(Portability)에 대한 향상
- 영향력(Impact)과 유용성(Usability) 증진
저자들은 위의 기초 5가지를 바탕으로 Design Principle 5가지를 정의합니다. 실제 프레임워크가 가장 중요하므로 여기는 빠르게 짚고 넘어갑니다.
- Comprehensiveness and Consistency
- CL 연구와 개발에 대한 End-to-End Support
- 모듈들 사이의 일관성 있고 쉬운 Interaction의 제공
- Ease-of-Use (Simplicity)
- “일단 사용하기 쉬워야 한다”
- 깔끔하고 직관적인 API 지원
- Repoducibility and Portability
- 논문 결과 재현하는 건 원래도 어려운데 CL에서는 악화되기 일쑤
- 우리 라이브러리에서는 Reproduce가 쉽도록 하자
- Modularity and Independence
- 각 모듈은 독립적으로 구성되어 있고 서로에게 의존하지 않는다
- Efficiency and Scalability
- Use Case나 Hardware Platform에 구애받지 않는 투명한 경험을 End-user에게 제공
Continual Learning Framework
먼저 Continual Learning을 다음과 같이 정의합니다.
- Continual Learning 알고리즘 \(A_{CL}\)
- 고정되지 않은 Experience들의 Stream에 의해 내부의 상태를 바꿈
- \(A_{CL}\)은 각 Experience \(e_1, e_2, ..., e_n\)에 순차적으로 노출됨
- \(A_{CL}\)의 목적은 특정 Metric들의 집합(\(p_1, p_2, ..., p_m\))에서 보여지는 성능을 높이는 것
- 각 Experience의 Test Stream(\(e^t_1, e^t_2, ..., e^t_n\))으로 측정됩니다.
Continual Learning의 기본적인 정의를 잡은 것으로 해석할 수 있습니다. Avalanche는 전체적으로 Customizable하고 확장성 있게 설계되었기 때문에, 대부분의 값이 가진 형태를 자유롭게 설정할 수 있습니다.
예컨대, Supervised Training 환경일 경우 각 Experience \(e_i\)는 다음과 같이 정의될 수 있겠습니다.
- 각 Experience \(e_i = \langle x_i, y_i, t_i \rangle\)
- \(x_i, y_i\)는 각각 Input과 그 Target을 나타냄
- \(t_i\)는 Task Label
- 추가 정보가 필요할 경우 자유롭게 선언할 수 있고, 없어도 됨
Main Modules
Avalanche는 총 5개의 Main Module들로 구성되어 있으며, 각각 다음과 같습니다.
Benchmarks
Avalanche에서 Benchmark 라는 어휘는 “원본 Dataset을 어떻게 가져오느냐에서부터 Stream의 내용, Example의 개수, Task Label 등에 의해 어떻게 Data의 Stream이 생성되는지를 명시한 레시피”로 해석됩니다.
말이 어렵지 그냥 원본 Dataset이 있을 때 이걸 어떻게 가져올지를 명시한다고 생각하면 될 것 같습니다.
Classic Benchmarks
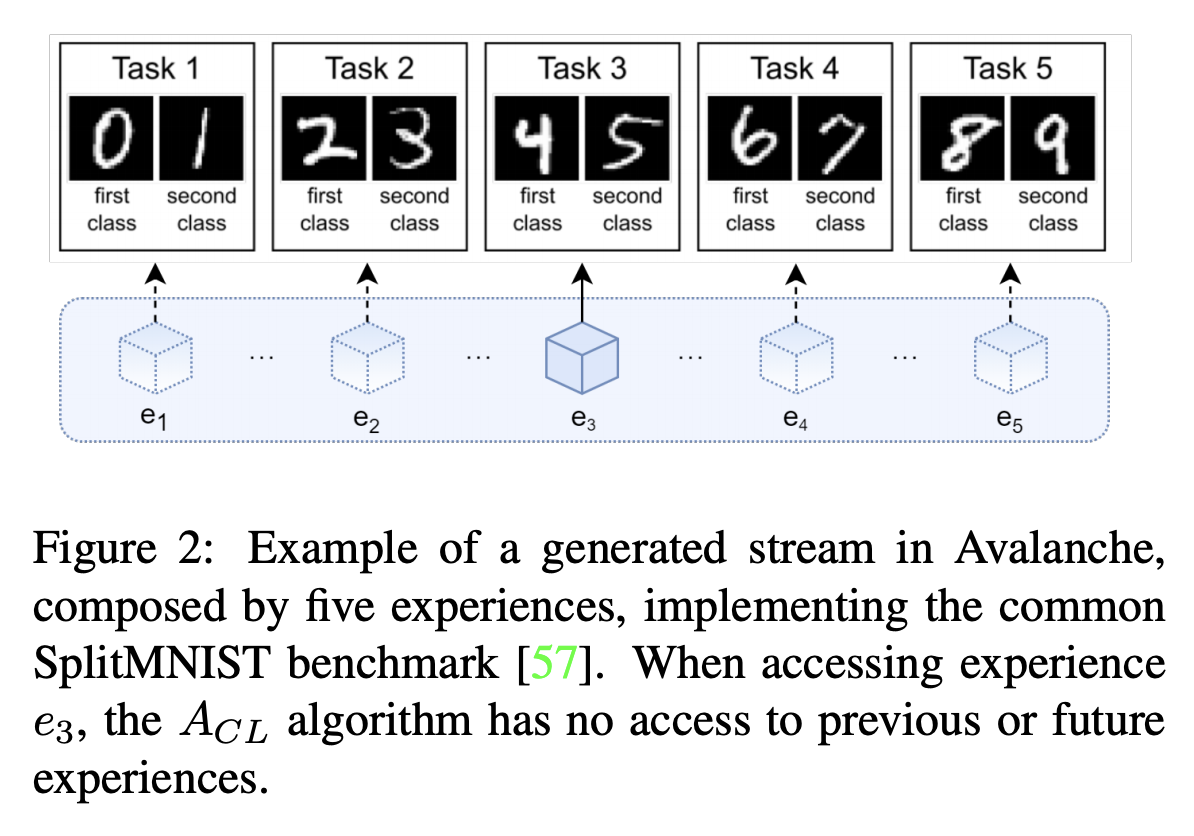
SplitMNIST를 사용한 Avalanche Benchmark의 예
예를 들어, Split MNIST Benchmark를 보겠습니다. 이것은 Continual Learning Through Synaptic Intelligence라는 논문에서 실험에 사용하려는 목적으로 만든 Benchmark로, MNIST의 각 숫자를 기준으로 Dataset을 5개의 Subset으로 나눈 것입니다.
만약 어떤 데이터가 우리가 살고 있는 세상의 일부분을 이루고 있으며 아직도 계속 생산되고 있다고 가정하겠습니다. 이것으로 CL을 하려고 한다면, 우리가 가져야 하는 데이터는 앞으로 생산될 데이터까지 몽땅 다 모아놓은 그 전체일 것입니다. 하지만 우리는 절대 그 데이터를 가질 수 없습니다. 아직도 생산되고 있으니까요. 그렇다면 우리는 그 데이터의 일부분을 가졌다고 생각한 상태에서 계속 추가 데이터가 들어올 것임을 상정하고 전략을 짜야 합니다.
각 시점 별로 획득한 데이터를 Experience로 보겠습니다.
그럼 0과 1로 구성된 Subset으로 훈련시킨 모델 \(M\)은 \(e_1\)에 노출(Exposure)되었다고 볼 수 있습니다.
그 뒤 새로운 데이터를 획득하였고 그게 2와 3으로 이루어진 데이터일 경우, 그것은 \(e_2\)가 되어 \(M\)에게 다시 노출됩니다.
그게 반복되는 것을 Continual Learning이라고 해석할 수 있고, 아까 위에서 내린 정의에 위와 같은 해석이 부합함을 알 수 있습니다.
Avalanche는 이런 형태의 Classic Benchmark를 다수 보유하고 있고, 이 Benchmark를 쉽게 다양한 형태로 확장할 수 있도록 설계하였습니다. 예컨대, SplitMNIST Benchmark를 만들 때 인자를 다르게 준다면 숫자 쌍에 쓰이는 각 숫자의 순서를 섞는 등의 수정을 가할 수도 있습니다. Customized Benchmark를 만들 수 있도록 하는 다양한 Tool들도 지속적으로 추가한다고 하니, 계속 업데이트를 지켜볼 필요가 있겠습니다.
다음은 SplitMNIST Benchmark를 Initialize하는 예제 코드입니다.
1
2
3
4
5
6
7
8
9
10
from avalanche.benchmarks.classic import SplitMNIST
benchmark_instance = SplitMNIST(
# Fundamental
n_experiences=5,
seed=1,
# Additional
return_task_id=True,
fixed_class_order=[5, 0, 9, ...]
)
이렇게 만들어진 Benchmark는 Avalanche와 완전히 독립적이며, 아예 따로 사용할 수 있을 정도로 모듈화되어 있습니다.
Scenarios
아무리 Classic Benchmark가 계속 생산된다고 해도, 분명히 어떤 Novel Benchmark를 만들어야 하는 상황이 존재합니다. 이 때를 위해서 Avalanche는 Scenario라는 개념으로 유연하게 사용할 수 있는 API를 제공합니다.
Scenario는 Benchmark보다 조금 더 일반적인(General) 형태의 레시피를 만들 수 있도록 해줍니다. 바로 코드부터 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
from avalanche.benchmarks.datasets import MNIST
from avalanche.benchmarks.generators import nc_scenario
mnist_train = MNIST('./mnist', train=True)
mnist_test = MNIST('./mnist', train=False)
benchmark_instance = nc_scenario(
train_dataset=mnist_train,
test_dataset=mnist_test,
n_experiences=n_experiences,
task_labels=True
)
우선 nc_scenario가 눈에 보입니다.
여기서의 nc는 New Classes 를 의미합니다.
New Classes Scenario는 모든 Class들을 특정 수의 Subset으로 주어진 Experience만큼 쪼개주는 Scenario입니다.
말 그대로 미리 정의된 Dataset에서 새로운 Class들이 지속적으로 나타나는 것을 상정한 시나리오를 만든 것이죠.
저 Scenario를 MNIST에 적용했으므로, SplitMNIST와 똑같은 모양이 됩니다.
Scenario가 제공하는 일반적임(General)이란 이런 식으로 정의됩니다. 어떤 Dataset을 넣던 그 데이터의 프로세스 자체를 정의함으로써 Benchmark를 다양한 형태로 확장할 수 있게 만든 것입니다. 사전 정의된 Scenario는 New Classes 말고도 New Instances, Multi Task, Single/Multi Incremental Task, Domain Incremental, Task Incremental 등 다양한 Case들을 다룰 수 있도록 준비되어 있습니다.
하지만 언제나 예외는 있는 법이고, Avalanche는 그것까지 고려해두었습니다. 파일을 직접 읽거나, PyTorch Dataset을 가져오거나, 아예 Tensor 자체를 불러오는 등의 작업을 할 수 있는 Generic Generator들도 아래처럼 준비되어 있습니다.
1
2
3
from avalanche.benchmarks.generators import (
filelist_scenario, dataset_scenario, tensor_scenario, paths_scenario
)
Streams
모든 데이터가 하나의 Stream만을 가지지는 않을 것입니다. 간단하게는 Validation Stream이 있을 수 있고, 어떤 데이터는 Out-of-distribution Stream도 가질 것입니다. Avalanche는 이 상황까지 고려해서, 각 Benchmark가 여러 개의 Stream을 가질 수 있도록 허용하였습니다. 정확히는 허용하려고 합니다. 현재는 Train과 Test Stream이 구현되었으며, 다른 Stream들에 대한 구현은 가까운 미래에 추가될 예정입니다.
우리는 각 Stream에 대해 Iterate하는 방식으로 Experience들을 얻어올 수 있습니다. 그리고 각 Experience는 각각을 나타내는 Index 값을 가지기 때문에 숫자로써 직접 Access할 수도 있습니다.
지금까지 알아본 것들을 바탕으로 Training Loop를 정의하자면, 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
train_stream = benchmark_instance.train_stream
test_stream = benchmark_instance.test_stream
for idx, experience in enumerate(train_stream):
dataset = experience.dataset
print('Train dataset contains', len(dataset), 'patterns')
for x, y, task_label in dataset:
# Train Step...
test_experience = test_stream[idx]
cumulative_test = test_stream[:idx+1]
Training
Avalanche의 학습 과정은 Strategy의 개념으로 표현되며, 각 Strategy는 train()과 eval()을 가집니다.
코드로 표현하면 다음과 같이 보여집니다.
1
2
3
4
5
6
from avalanche.training.strategies import Naive
strategy = Naive(model, optimizer, criterion, ...)
for train_exp in scenario.train_stream:
strategy.train(train_exp)
strategy.eval(scenario.test_stream)
여기서 보여지는 Naive Strategy는 단순한 학습을 의미합니다. 이런 기본적인 Strategy부터 시작해서 총 11가지의 Strategy가 사전에 준비되어 있습니다.
Customizing
지금까지 계속 그랬듯, Avalanche는 Custom Strategy를 허용합니다.
BaseStrategy라는 클래스가 있고, 이것이 확장되는 형태입니다.
BaseStrategy.train()을 개략적으로 표현하면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def train(exps):
before_training()
for exp in experiences:
train_exp(exp)
after_training()
def train_exp(exp):
adapt_train_dataset()
make_train_dataloader()
before_training_exp()
for epoch in range(n_epochs):
before_training_epoch()
training_epoch()
after_training_epoch()
after_training_exp()
사이사이에 Callback 같은 것들이 숨어있습니다.
마치 TensorFlow Keras의 model.fit() 내부 구현처럼 되어있습니다.
이렇게까지 많은 부분에 Hook을 심어두었으니, 저 Hook들을 재구현하는 것만으로도 어떤 Training 형태든 만들 수 있을 것으로 보입니다.
Plugins
그리고 위에서 설명한 Hook들을 역할 별로 정의하기 위한 방법으로 Plugin 시스템이 있습니다. 참 꼼꼼하게 다양한 관점에서 고민해서 잘 만들어두었다는 생각이 들었습니다.
다음은 그 코드입니다. TF의 model.fit()에 넘기는 callbacks=[] 인자와 닮아있습니다.
1
2
3
4
5
6
7
replay = ReplayPlugin(mem_size)
ewc = EWCPlugin(ewc_lambda)
strategy = BaseStrategy(
model, optimizer,
criterion, mem_size,
plugins=[replay, ewc]
)
Evaluation & Logging
Avalanche는 Design Principle에 따라 어떤 것을 볼지(What to Monitor)와 어떻게 볼지(How to Monitor)를 구분하여 생각하고 있으며, 각각이 Evaluation 부분과 Logging 부분으로 나눠집니다.
그런데, 이 개념이 아주 깔끔하게 Plugin의 형태로 합쳐져서 들어갑니다. 아래 코드를 보면 모든 것을 이해할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
text_logger = TextLogger(open('out.txt', 'w'))
interactive_logger = InteractiveLogger()
tensorboard_logger = TensorBoardLogger()
eval_plugin = EvaluationPlugin(
# Metrics
accuracy_metrics(experience=True),
loss_metrics(minibatch=True, epoch=True, stream=True),
ExperienceForgetting(),
StreamConfusionMatrix(num_classes=n_classes, save_image=False),
cpu_usage_metrics(experience=True),
timing_metrics(epoch=True),
ram_usage_metrics(epoch=True),
gpu_usage_metrics(gpu_id, epoch=True),
disk_usage_metrics(minibatch=True, epoch=True, experience=True)
MAC_metrics(minibatch=True),
# Loggers
loggers=[
interactive_logger, text_logger,
tensorboard_logger
]
)
할 말을 잃는 수준으로 많은 Metric들이 사전 정의되어 있습니다. CPU/RAM/GPU 같은 것들은 보통 머신러닝 프레임워크에서 직접 Metric으로 찍는 것이 쉽지 않은데, 그것들까지 하나의 인터페이스로 통합해두었다는 점이 놀라웠습니다. Less Code와 High Efficiency를 동시에 예쁘게 취하기가 쉬운 것이 아닌데, 정말 잘 구성해두었다는 생각이 듭니다.
Models
Avalanche의 models 모듈에는 다음과 같은 모듈들이 사전 정의되어 있습니다.
- 몇 가지의 Feed Forward & Convolutional Neural Network들
- MobileNetV1의 Pretrained Version
연구자들이 특정 Architecture를 구현하는 데 시간을 쏟기 보다는 Avalanche의 기능에 집중할 수 있도록 돕기 위해서 이 모듈을 넣었다고 합니다. 대부분의 경우 Model을 직접 개발한 후 이 프레임워크에 얹는 형태일테니, Building Block으로써 요긴하게 기능할 수는 있을 듯 합니다.
후기
“어떻게 하면 Continual Learning을 잘 추상화해서 표준화할 수 있을까”에 대한 고민을 많이 한 흔적이 보이는 프레임워크라는 인상을 크게 받았습니다.
현대의 머신러닝 라이브러리들 중에는 너무 과도한 수준의 추상화를 적용한 형태를 갖고 단지 코드 몇 줄 만으로 많은 일을 할 수 있게 만든 것들이 많은데, 저는 이런 라이브러리들이 당장은 편해도 결국 연구자나 엔지니어의 행동을 제약하고 자유로운 커스터마이즈를 거의 불가능하게 만든다고 생각합니다.
사실 Avalanche를 처음 봤을 때도 추상화 수준이 높으니 사용성이 같이 높지는 않을 것이라고 생각했는데, 보면 볼 수록 여러 측면에서 깊이 고민해서 잘 빚어내었다는 생각이 들게 만드는 프레임워크였습니다.
앞으로 Avalanche가 더욱 많이 발전해서, 진짜 눈사태처럼 커뮤니티에 규모 있는 드라이브를 걸어 여러 복잡하고 Challenging한 문제들을 푸는 발판으로써 기능할 수 있었으면 좋겠습니다.