
PyTorch Ecosystem Day 2021
한국 시간으로 4월 22일 오전 12시부터 오전 10시까지 PyTorch Ecosystem Day 2021가 열렸습니다. 당연하겠지만 APAC의 낮에는 절대 허락되지 않는 Keynote 시간이었기에 거의 밤새다시피 하면서 들었습니다. PyTorch가 주변 생태계를 얼마나 소중하게 생각하고 Support하려고 하는지를 느낄 수 있었고, 새로운 라이브러리나 기능들을 많이 접할 수 있었던 시간이었습니다. 제가 관심을 두고 있는 부분들만 따로 모아서 정리하기 위해 이 글을 씁니다.
Keynote
Keynote 접속에 약간의 장애(…)가 있었어서, 중간부터 듣기 시작했다. ‘예수 형’으로 불리는 Piotr Bialecki (@ptrblck)의 파트를 보지 못해서 아쉽긴 하지만, 중요하다고 생각되는 부분들은 전부 들어서 다행이었다.
PyTorch Profiler
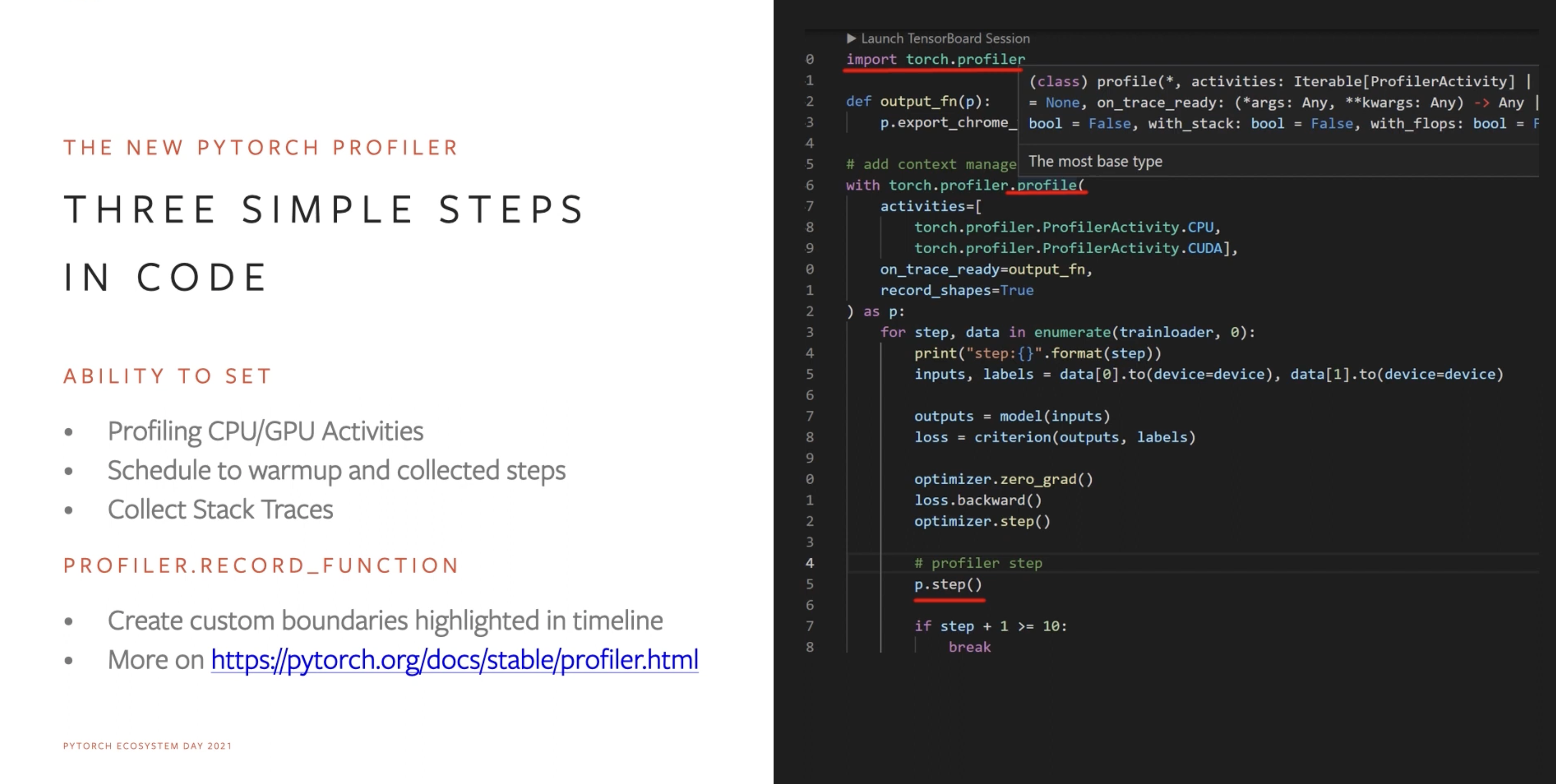
PyTorch Profiler
사실 만들고 있던 것은 지난 PyTorch Developer Day에서 들어 알고 있었지만, 상세한 기능까지 소개된 것은 처음 보았다. 대체적으로 TF를 사용할 때 TensorBoard의 PROFILE 탭을 보는 느낌으로 잘 구성해두었다. 발표에서 소개된 기능들은 다음과 같다.
- Timeline Tracing
- Profiling이 진행된 시간 동안의 GPU/CPU의 동작과 어떤 작업이 있었는지 볼 수 있는 View
- Stack Trace
- Op들이 실행되는 순서와 그 Callstack을 볼 수 있는 View
- Kernel View
- Step Time에서 각 Op들이 차지한 시간의 비율을 모아 볼 수 있는 View
- Operator View등 더 많은 View들
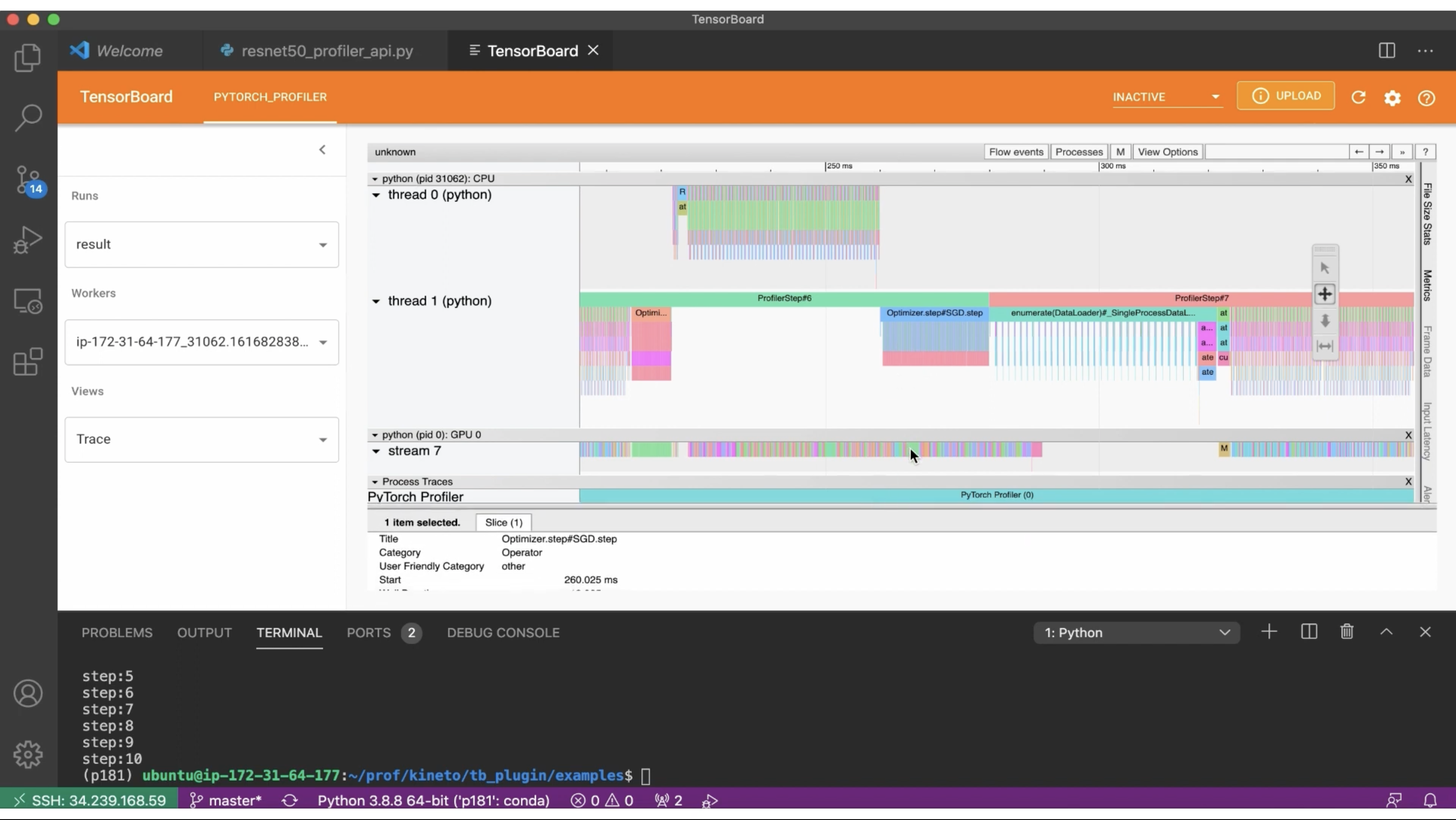
PyTorch Profiler - Trace View
아무래도 기존의 torch.autograd.profiler가 이렇게까지는 자세하게 보여주지 않아서 불편한 점이 많았는데, 이제 이렇게 TensorBoard로 잘 정리해서 보여주니 Training 속도 최적화나 병목 분석 같은 작업을 할 때 크게 도움될 것 같다.
한 가지 더 고무적이었던 점은, 여기에서 설명하는 CPU/GPU용과 다른 XLA/TPU 환경에서의 Profiler가 소개되었다는 것이다. Google과의 협업으로 PyTorch/XLA 환경의 Cloud TPU VM이 소개되면서 같이 나왔는데, 이 내용은 하단의 Poster에서 살펴본다.
torch.fx

torch.fx의 예시
torch.fx라는 이름으로 새로운 라이브러리 확장이 발표되었다.
이걸 사용하면 nn.Module을 Trace해서 torch.fx.Graph로 만들 수 있다고 하며, 이 Graph는 Module 내부의 Op들이 구성하는 실행 순서를 빌드해서 객체화한 것이라고 해석하면 될 듯 하다.
Reference에서는 이걸 Symbolic Trace했다고 하며, Module이 가지는 Semantic을 Capture한 것이라고 설명했다.
아래 코드를 통해 확실히 감을 잡을 수 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import torch
# Simple module for demonstration
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
module = MyModule()
from torch.fx import symbolic_trace
# Symbolic tracing frontend - captures the semantics of the module
symbolic_traced : torch.fx.GraphModule = symbolic_trace(module)
# High-level intermediate representation (IR) - Graph representation
print(symbolic_traced.graph)
"""
graph(x):
%param : [#users=1] = self.param
%add_1 : [#users=1] = call_function[target=<built-in function add>](args = (%x, %param), kwargs = {})
%linear_1 : [#users=1] = call_module[target=linear](args = (%add_1,), kwargs = {})
%clamp_1 : [#users=1] = call_method[target=clamp](args = (%linear_1,), kwargs = {min: 0.0, max: 1.0})
return clamp_1
"""
# Code generation - valid Python code
print(symbolic_traced.code)
"""
def forward(self, x):
param = self.param
add_1 = x + param; x = param = None
linear_1 = self.linear(add_1); add_1 = None
clamp_1 = linear_1.clamp(min = 0.0, max = 1.0); linear_1 = None
return clamp_1
"""
Graph의 Representation을 들고 있으니 Python Code까지 생성해낼 수 있도록 설계되었다. 이 개념 자체도 상당히 인상적이었지만, 더욱 큰 가능성은 Transform에서 볼 수 있었다. 아래 코드에서 바로 감이 올 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import torch
import torch.fx
def transform(m: nn.Module,
tracer_class : type = torch.fx.Tracer) -> torch.nn.Module:
# Step 1: Acquire a Graph representing the code in `m`
# NOTE: torch.fx.symbolic_trace is a wrapper around a call to
# fx.Tracer.trace and constructing a GraphModule. We'll
# split that out in our transform to allow the caller to
# customize tracing behavior.
graph : torch.fx.Graph = tracer_class().trace(m)
# Step 2: Modify this Graph or create a new one
graph = ...
# Step 3: Construct a Module to return
return torch.fx.GraphModule(m, graph)
nn.Module -> nn.Module 변환을 수행하는 함수라고 볼 수 있는데, 그 과정에서 특정 Module의 Graph를 수정할 수 있다.
이 기능은 특정 Module에 어떠한 특성을 범용적으로 부여하는 함수를 구현해야 할 때 굉장히 편리하게 사용할 수 있을 것 같다.
예를 들어, 특정 Module을 Quantize하고 싶고, 내부의 Weight을 일괄적으로 INT8로 형변환해주고 싶다고 하자. 그럼 Transform 함수를 짜서 모든 Weight에 대해서 Type Cast를 하면 될 일이며, Layer Normalization과 같이 함부로 Precision을 낮추면 안되는 컴포넌트가 있을 때에도 Graph에서 해당 Op을 식별해서 그 Op은 내리지 않게도 할 수 있을 것이다. 정말 무궁무진한 활용 방법들이 있을 것 같다.
…라고 생각했는데 Poster 세션에서 torch.fx를 사용한 Quantization을 수행하는 것을 봤다.
역시 Poster에서 살펴보기로 하자.
Pipeline Parallelism

Pipeline Parallelism 지원
torch.distributed 패키지 하위에 Pipeline Parallelism을 위한 툴들이 추가되었다.
보자마자 바로 생각난 건 카카오브레인에서 이전에 만들어서 공개한 torchgpipe였다.
Reference 문서를 들어가봤는데, 아니나 다를까 torchgpipe Paper를 참조해서 만들었다고 명시가 되어있다. 만드신 분들은 참 뿌듯할 것 같다.
지난 DevDay 2020에서 Torch RPC가 공개된 바 있었는데, 그것을 사용해서 구현했겠지 싶어 더 살펴보니 forward() 함수가 torch.distributed.rpc의 RRef를 반환한다. 나중에 RPC 구현 예제 삼아서 더 깊숙히 뜯어봐야겠다.
지금은 Pipe와 Skip Connection 핸들링 관련 특정 기능들만 구현되어있다. 한참 발전해야겠지만, 이제 공식 라이브러리의 일부로 편입되었으니 기대감을 갖고 바라보아도 좋겠다. 물론 이전에 FairScale에서 Pipe 구현을 선보인 적이 있으나, 이제 구현이 여기로 넘어왔으니 둘 사이에 어떤 차이가 생길지도 더 지켜봐야 한다. 또 Torch RPC를 기반으로 짜두었으니 필요에 따라서 추가 라이브러리 없이 직접 수정해서 짜봐도 재미있을 것 같다는 생각을 했다.
Partner Integrations
PyTorch 팀 일한다! Keynote에서 말이 겁나 빠른(…) Partnership 담당자가 나와서 별도의 세션으로 외부와의 협업 사례를 소개했는데, 이번에 특히 이 부분이 두드러지게 나타났을 정도로 협업 사례가 많이 있었다. 그 중 많이 와닿았던 3가지 사례를 정리한다.
Visual Studio Code Integration (w/ Microsoft)
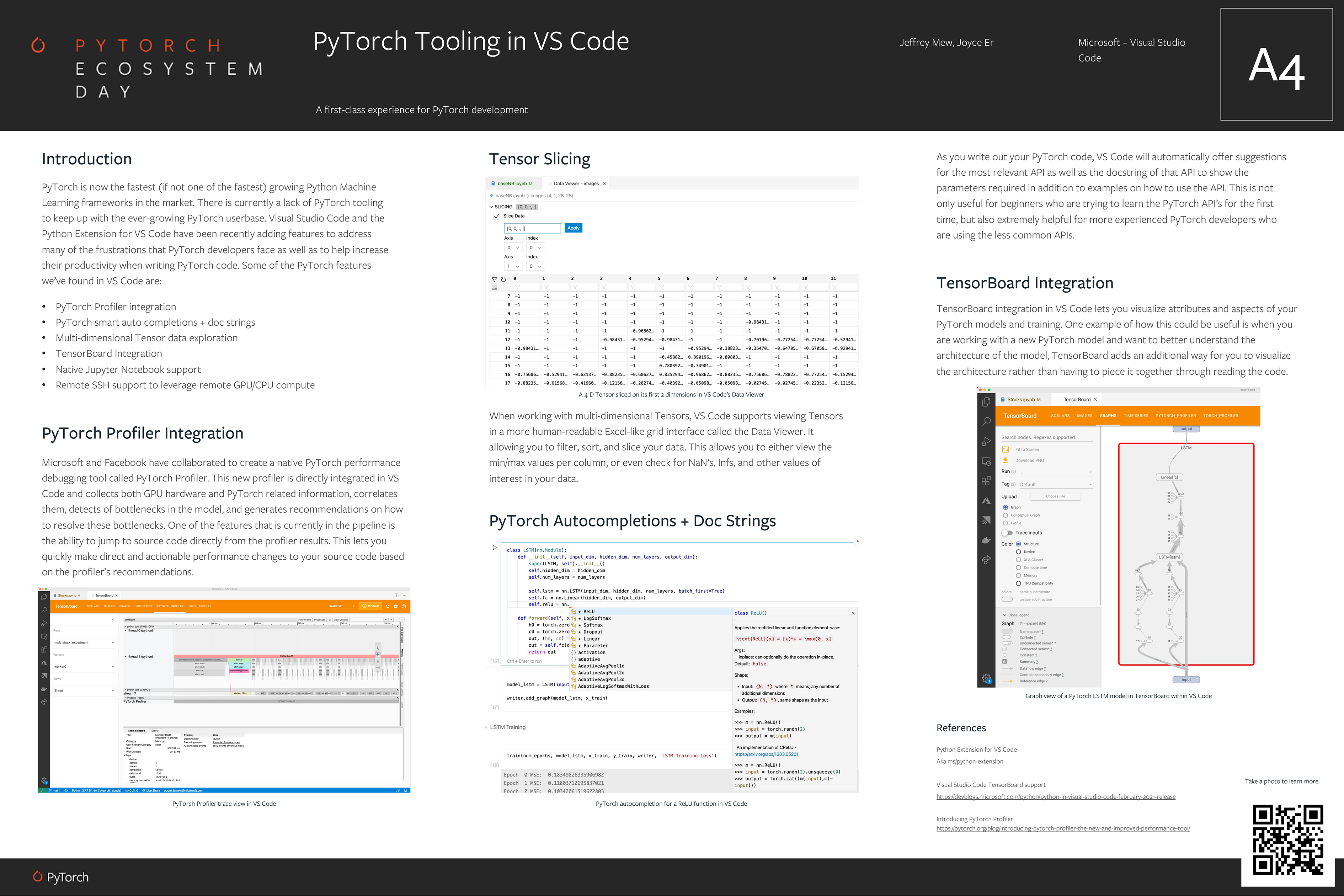
PyTorch Tooling in VS Code (Poster)
Microsoft는 항상 PyTorch 생태계에 큰 기여들을 해왔고, DeepSpeed부터 시작해서 이쪽에 관심이 많음이 느껴진다. 이번에도 Facebook과 함께 다양한 기여들을 했는데, Visual Studio Code 관련 연동이 Poster 세션에서 따로 소개될 정도로 자세하게 나왔다.
- PyTorch Profiler
- 위에서 소개한 Profiler가 VS Code에 Directly Integrated 되었다고 한다.
- 그냥 TensorBoard VS Code Plugin에다가 Profiler 띄워놓은 거 아닌가? 더 살펴봐야 할 것 같다.
- Tensor Slicing
- 스크립트 상의 Multi-dimensional Tensor를 엑셀 비슷한 UI로 뜯어볼 수 있게 해둔 모양이다.
- 학습 스크립트 디버깅할 때 큰 도움이 될 것 같아서 크게 기대하고 있는 기능 중 하나.
- PyTorch Autocompletions + Doc Strings
- VS Code의 Intellisense 기능이 PyTorch에 적용된 것 같다.
- 생산성에 크게 도움될 것 같아서 얼른 사용해봐야겠다는 생각이 들었다.
- TensorBoard Integration
- TensorBoard가 VS Code 상에 창의 형태로 뜨는 기능. 이전부터 Extension으로 있었다.
- 큰 도움은 안되긴 했다. TPU처럼 Cloud 원격 학습하는 경우에는 이것보다 웹 뷰가 더 편했다.
MLFlow Integration (w/ Databricks)
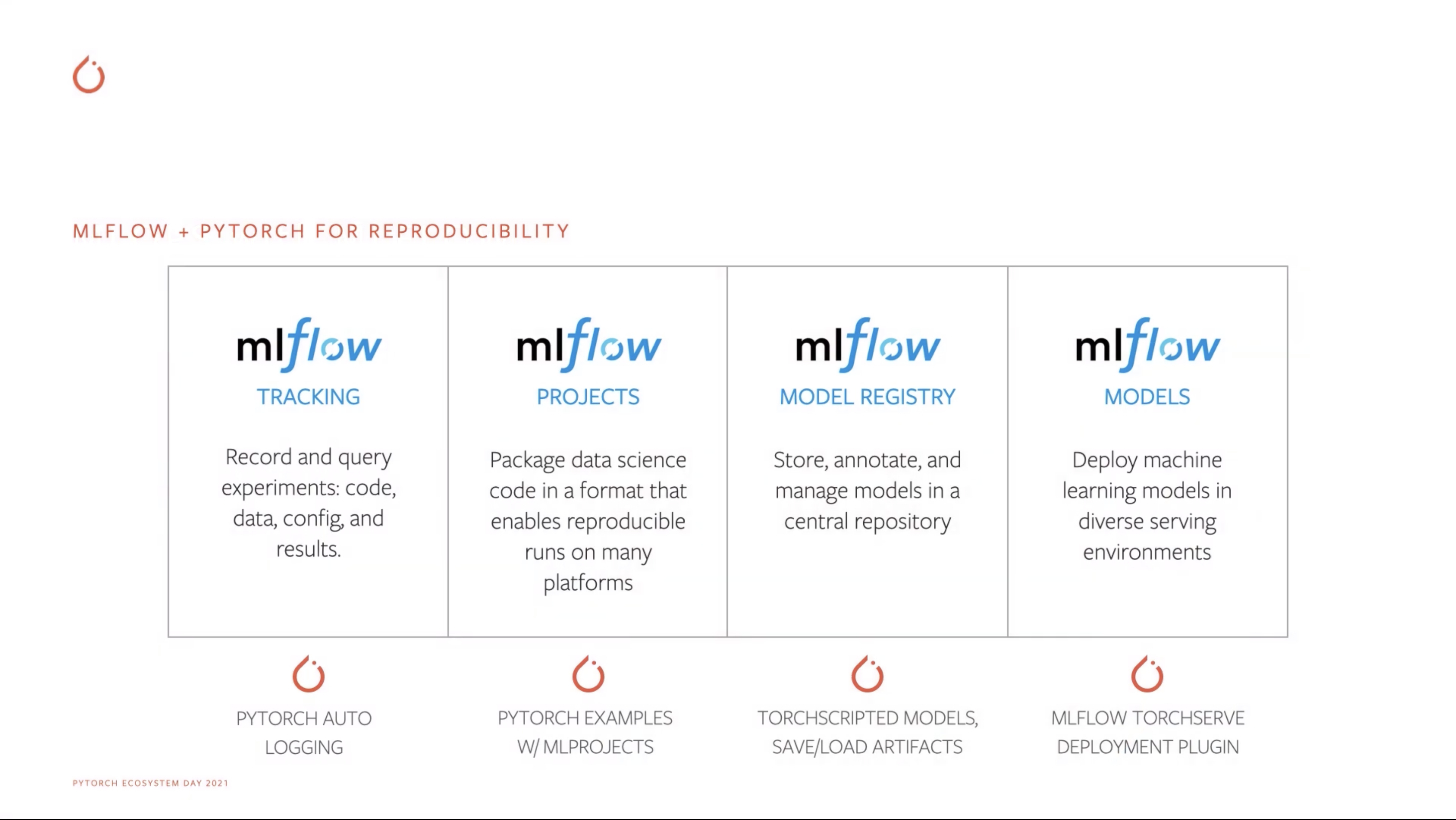
MLFlow Integration
최근 MLFlow를 회사에서 전체 팀 규모로 관리하면서 써보자는 이야기를 하고 있었어서 눈길이 많이 갔던 발표였다. Databricks와의 협업으로 아예 제대로 붙잡고 연동시킨 듯 하다.
- MLFlow Tracking
- TensorBoard 상위 호환 기능으로, Experiment > Run 구조로 로깅을 지원한다.
- PyTorch Auto Logging에서 편리하게 지원하는 듯 하다. 각 잡고 살펴봐야 할 듯.
- MLFlow 문서:
mlflow.pytorch.autolog
- MLFlow Projects
- 프로젝트 코드를
Project의 단위로 감싸서 관리할 수 있다. - Torch의 Example 코드들을 이것으로 묶어서 제공하는 듯. (이걸 연동이라고 할 수 있나?)
- 프로젝트 코드를
- MLFlow Model Registry
- 만들어진 모델들의 버전 관리를 해주는 컴포넌트.
- TorchScript로 Trace된 모델들의 등록과 Artifact들의 저장/로딩을 지원한다.
- MLFlow Models
- 등록된 모델을 배포해주는 컴포넌트.
- TorchServe의 Deployment Plugin이 추가되었다. 모델의 API 내부 테스트 시 도움이 될 것 같다.
Kubeflow Pipelines Integration (w/ Google)
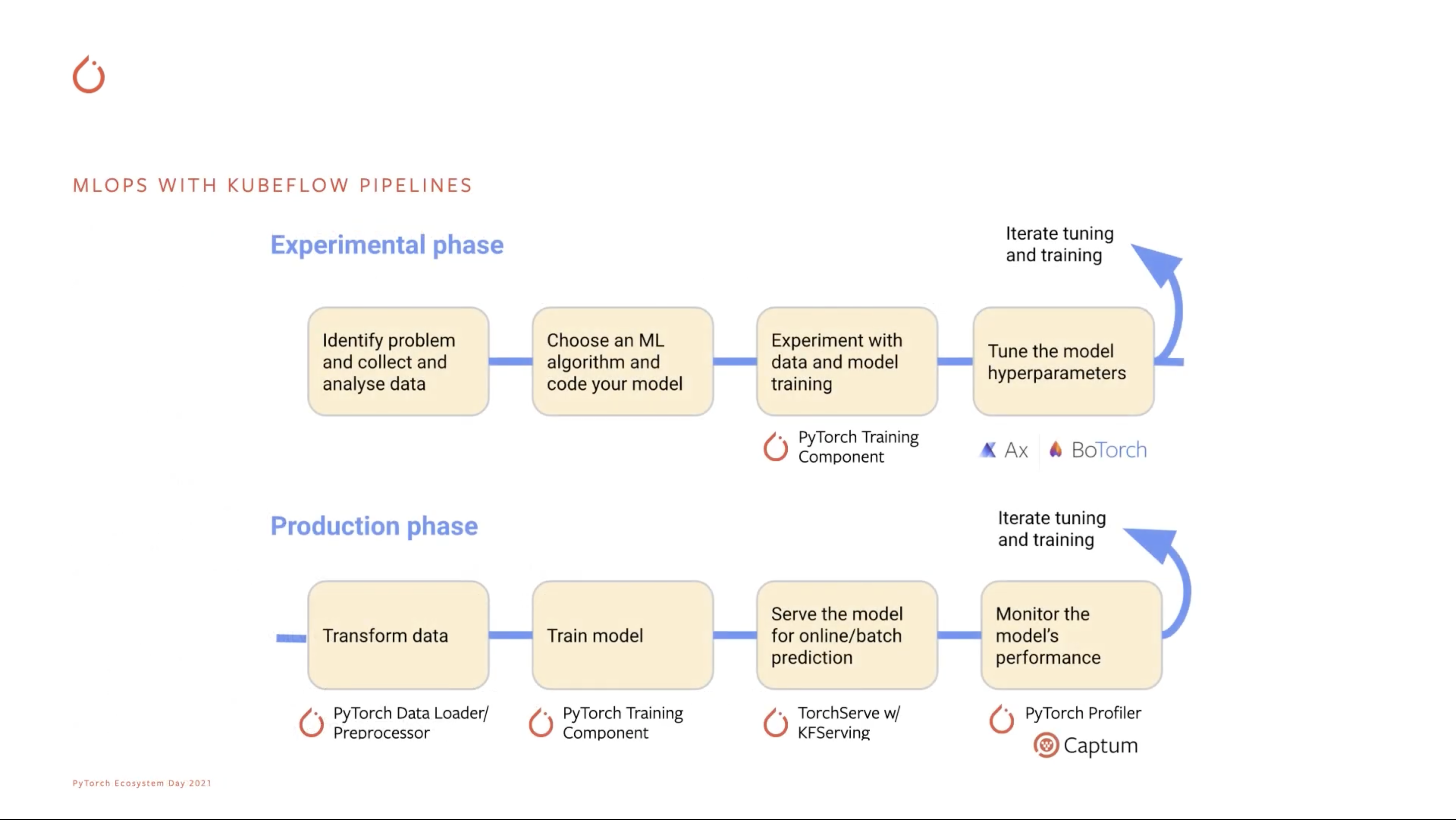
Kubeflow Pipelines + PyTorch
Google과의 큰 협업 사례 중 하나로, Kubeflow Pipelines에서 MLOps 파이프라인의 형태로 사용할 수 있도록 컴포넌트화했다고 한다. Kubeflow Pipelines가 TFX를 사용할 때 제일 잘 맞아떨어지다 보니 PyTorch 중심의 파이프라인은 어떤 형식일까를 생각해본 적이 있어서, 이런 움직임은 크게 기대되는 부분이다.
제일 눈길이 갔던 건 아래 두 컴포넌트다.
- PyTorch Training Component
- TFX의
Trainer와 비슷한 위치라고 생각했다. - 최근에 나온 건 찾아볼 수 없었고, 2년 전 쯤 나온 PyTorch Training이 있긴 하다.
- 그냥 Training Step에서는 이걸 쓰면 된다고 하는 듯. 약간의 실망.
- TFX의
- TorchServe w/ KFServing
- KFServing의 Model Server Backend로 TorchServe를 사용할 수 있는 듯.
- TF는 TFServing, Torch는 TorchServe로 KFServing 뒤에 둔다고 하면 연구 조직과 엔지니어링 조직 양쪽의 니즈를 모두 만족시킬 수 있을 것 같다.
- 문제는 성능인데, 어떻게 나올지는 궁금하다.
Poster
이번 행사에는 정말 많은 Poster들이 있었다. 여기에 소개하는 내용 말고도 흥미로운 내용이 정말 많았으나, 우선 주로 흥미로웠던 세션들을 따로 모아서 정리한다.
PyTorch/XLA TPU VM
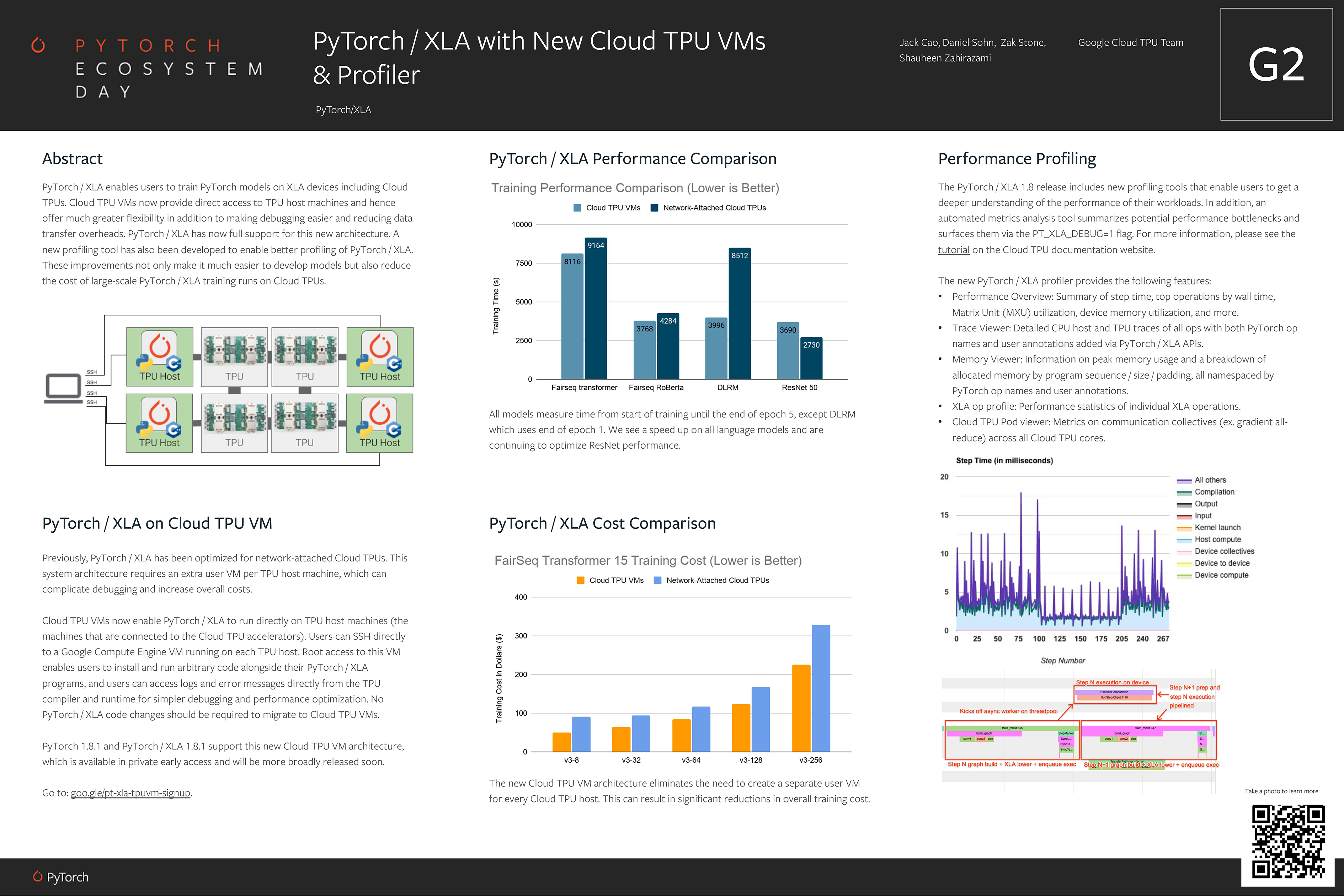
PyTorch/XLA TPU Support Poster
기존에는 TPU를 사용하기 위해서 GCP Project에 VM을 띄우고 원격으로 TPU VM과 연결되어 작업을 수행하는 형태로 학습했다. 그러다보니 디버깅도 굉장히 어려웠고 Dataset이 Local VM에 있을 때도 그걸 전송하는 시간이 Training Overhead에 들어가버려서 최적화가 굉장히 힘들었다.
TensorFlow에서는 그나마 dataset.interleave() 함수를 사용하면 TPU VM에서 Google Cloud Storage에 있는 여러 TFRecord 파일들을 Interleaving하는 방식으로 로딩해서 Data Streaming에 드는 Overhead를 줄일 수 있었는데, PyTorch에서는 그런 거 없었어서(…) 기본적으로 느린 속도를 가정하고 시작해야 했다.
하지만 이 발표에 따르면, TPU VM에 직접 SSH 연결을 수립해서 들어갈 수 있다는 것 같다. 포스터 상에 나와있는 Performance를 보면 모든 Language Model에서 성능 향상을 꾀할 수 있어 보이고, 심지어 VM을 따로 띄우지 않으니 Training Cost($)까지도 줄일 수 있다고 한다! 거기다 새로운 PyTorch/XLA Profiling Tool까지 제공해준다고 하니, TPU 쓰는 사람 입장에서는 무야호를 외치지 않을 수 없다. 이런 협업 너무 좋고, 앞으로도 많이 해주셨으면 좋겠는 바람이다.
이후 포스터 하단의 Alpha Signup을 했는데, 일부 인원들에게만 공유하는 TPU VM 접속 방법이 담긴 문서를 공유받았습니다. 관심 있으신 분들은 신청해보시면 바로 직접 실험해보실 수 있고, Google 직원과 직접 소통할 수 있는 Chatroom에서 대화할 수도 있는 듯 합니다!
torch.fx를 활용한 Quantization

FX Graph Mode Quantization Poster
위에서 알아봤던 torch.fx를 사용해서 만든 Quantization 기능이다.
구현한 모델이 FX Graph에 맞는 구조로 되어있기만 하다면, 자동으로 Quantization을 하도록 구성할 수 있다고 한다.
Post Training Quantization은 물론이고, Quantization-aware Training 또한 잘 지원된다.
다음 코드에서 그 예시들을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from torch.quantization import prepare_fx, convert_fx, default_qconfig
qconfig_dict = {"": default_qconfig}
# Post Training Quantization
model_to_quantize.eval()
prepared_model = prepare_fx(model_to_quantize, qconfig_dict)
quantized_model = convert_fx(prepared_model)
# Quantization-aware Training
model_to_quantize.train()
prepared_model = prepare_qat_fx(model_to_quantize, qconfig_dict)
quantized_model = convert_fx(prepared_model)
잘만 사용하면 큰 공수를 들이지 않고 Quantized Model을 얻을 수 있을 것 같다. 이런 편의 기능에서 늘 걱정되는 점은 얼마나 Customizable하게 구성되었느냐이다. Layer Normalization이나 Embedding Layer 등 Quantization으로 인한 성능 하락이 민감하게 작용하는 부분이 어느 모델에나 있을텐데, 이런 것들은 변환 과정에서 제외해주어야 할 것이다.
위 예제의 default_qconfig에서 볼 수 있듯 외부에서 Config를 넣어주는 방식으로 Customize를 다루었다.
1
2
3
prepare_custom_config_dict = {
"additional_quant_pattern": (torch.bmm, BMMQuantizeHandler)
}
torch.bmm 하위 모듈이면 BMMQuantizeHandler를 사용하도록 하는 구성이다.
위에서 언급했던 사례는 이것으로 얼추 해결될 듯 한데, 저 XXXQuantizeHandler가 어디까지 핸들링할 수 있는지는 더 자세히 알아봐야 할 것 같다.
Amazon EC2 Inf1과 TorchServe의 연동

Amazon EC2 Inf1 & TorchServe
AWS에서 Inferentia라는 칩이 소개된 적이 있었다. 이 칩에는 NeuronCore라는 코어가 심어져 있고, 머신러닝 추론 가속만을 위하여 디자인되었다고 한다. FP16이나 BF16, INT8 타입을 Mixed Precision과 함께 지원하는 것을 보고 AWS에서 Production에서 쓰는 Quantized Model 추론은 여기서 하라는 의도로 출시한 칩이라고 생각했다. 이번에 소개된 내용은 Neuron SDK로 Torch 기반의 모델을 Trace하고 그걸 TorchServe를 사용해서 Inf1 칩에서 추론하는 과정이었다.
1
2
3
4
5
6
import torch
import torch_neuron
neuron_model = torch.neuron.trace(model, example_inputs=(inputs["input_ids"]))
#...
neuron_model.save('model-name.pt')
위와 같은 코드를 사용해서 Traced Model을 외부에 Save할 수 있고, TorchServe에서 이걸 로딩하면 Neuron Runtime에서 서빙할 수 있다.
도표를 통해 Cost는 싸고, Latency는 낮고, Throughput은 높다고 보여주고 있다.
거기다 Amazon EKS에서 Neuron 관련 리소스 선언 플러그인을 eksctl에 기본으로 설치해준다고 하며, 다음과 같은 활용이 가능하다고 한다.
1
2
3
4
5
6
7
8
containers:
- names: torchserve-neuron-test
images: 1111.dkr.cr.us-east-1.amazonaws.com/torchserve-neuron-test:latest
resources:
limits:
cpu: 4
memory: 4Gi
aws.amazon.com/neuron: 1
resources.limits 조건에 aws.amazon.com/neuron을 설정해주면 Inf1 칩에 Pod이 뜨도록 구성된다.
Neuron 칩을 Node의 Physical한 요소로 등록할 수 있도록 커스텀해둔 것으로, 모델을 Production 환경에서 서빙할 때를 잘 고려해둔 것으로 보인다.
기회가 되면 TFServing 대신 TorchServe + Neuron으로 서빙해보고 속도 차이가 얼마나 나는지도 실험해보고 싶다.
DeepSpeed
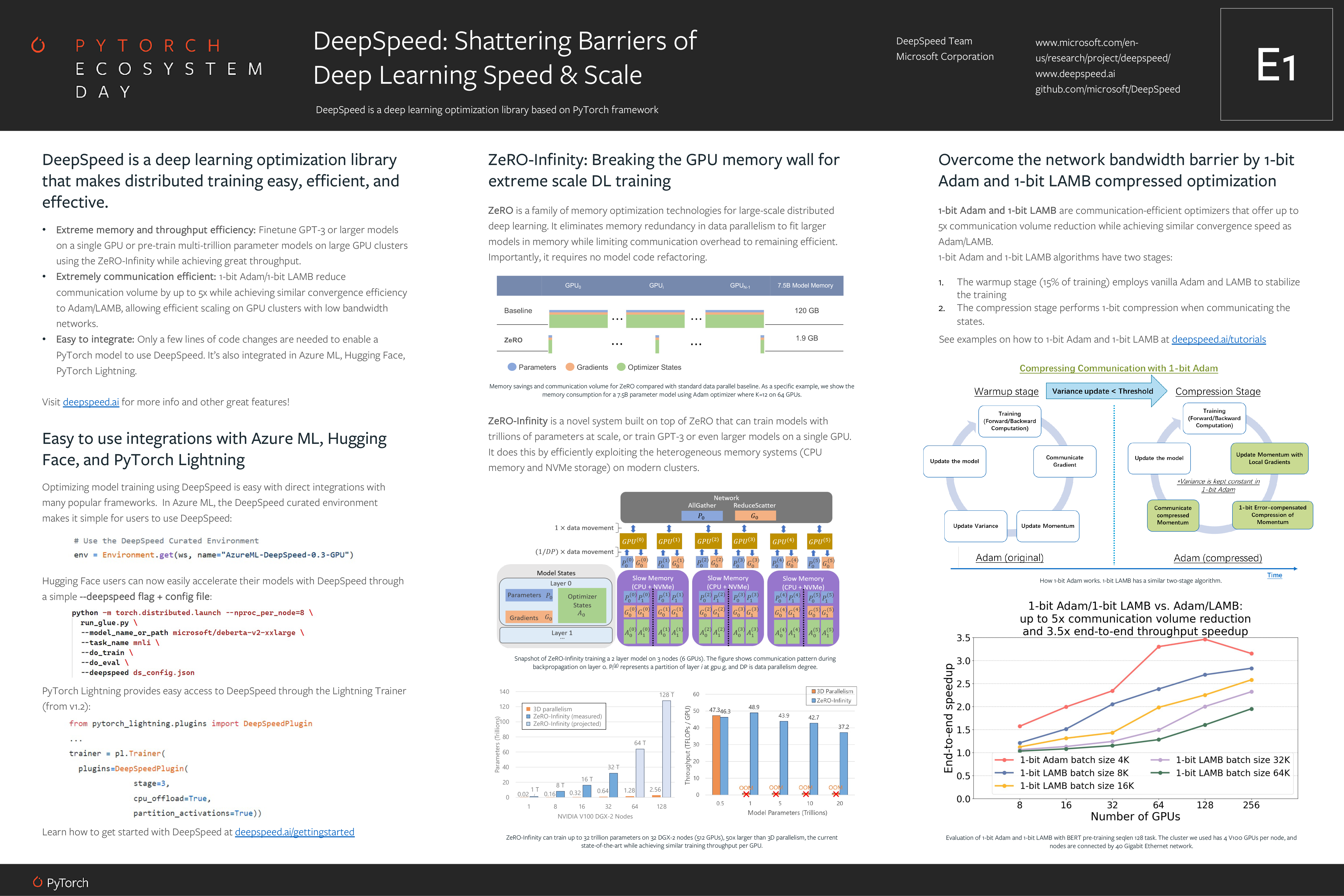
DeepSpeed Poster
최근 Billion 크기의 모델을 만들면서 깊게 뜯어봤던 라이브러리인지라 이번에도 주의 깊게 들여다보았다.
먼저 Azure ML, HuggingFace, PyTorch Lightning과의 라이브러리 연동이 있었다.
HuggingFace의 경우 기존의 DeepSpeed와 비슷하게 torch.distributed.launch 모듈을 활용하고 있었다.
PyTorch Lightning은 Plugin의 형태로 제공되었고, stage 파라미터와 함께 부수적인 Keyword Argument들을 넣어주면 DeepSpeed Configuration이 만들어지는 것 같다.
예제의 stage에 3이 적혀있어서 깜짝 놀라 찾아보니, 어느 새 DeepSpeed가 ZeRO Optimization 3단계까지 지원하고 있음을 발견했다.
2까지만 테스트해보았는데, 이것도 어느 정도의 성능이 나오는지 추후 테스트해봐야 할 것 같다.
그리고 ZeRO-Infinity가 소개되었는데, 이 내용은 논문에도 자세히 나와있으므로 설명은 건너뛴다. 흥미로웠던 점은 큰 Throughput 감소 없이 큰 모델을 Training할 수 있다고 하면서 그 예로 든 도표에서 128 T 규모를 그려두었다는 점이다. 대체 어디까지 바라보고 있는지 궁금하다. GPT-3 128T 버전 곧 만들어주는 건가?
마지막으로 1-bit Adam과 1-bit LAMB가 소개되었다. Up to 5x communication time reduction을 보이면서 동시에 일반적인 Adam/LAMB과 비슷한 수렴 속도를 보인다고 한다. 도표에 따르면 거의 3.5배의 End-to-end throughput speedup이 있다고 하는데, 직접 해봐야겠다.
후기
굉장히 유익하고 재미있는 행사였습니다. 생각보다 PyTorch Ecosystem이 빠른 속도로 크게 성장하고 있고, 그 뒤에는 강력한 Community Support와 여러 기업들 간의 협업이 있었음을 발견했습니다. PyTorch는 특유의 On-the-fly Graph 구성 방식 때문에 연구 환경에서는 강력하지만 Production Serving 쪽에 많이 약하다는 인식이 많은데, 이렇게 점점 발전해서 Serving에서도 좋은 프레임워크로 발돋움했으면 하는 바람입니다.

새벽 행사에서 마주쳐서 더 반가웠던 분 :)
-
Previous
TensorFlow Custom Op으로 데이터 변환 최적화하기 -
Next
Avalanche: an End-to-End Library for Continual Learning - Paper Review