추론 속도와 메모리 효율성을 위해 BERT를 8Bit Integer로 Quantize하는 방법론을 제시했으며, NeurIPS 2019에 소개되었습니다. BERT를 Accuracy를 최대한 보존한 상태에서 4분의 1 크기로 줄였습니다.
Introduction
최근에 SOTA를 찍고 있는 BERT와 같은 모델들은 매우 큰 Corpora와 Parameter를 사용하여 학습됩니다. 그렇기 때문에 추론 시에 많은 연산량과 메모리를 소모하고 큰 대역폭을 차지하게 됩니다. 하지만 실제 서비스 영역으로 나아가게 되면 이런 특징들은 추론 서버를 만드는 데 큰 장애물로 작용합니다.
이 논문에서는 다음의 방법을 사용해서 BERT의 Compression 대비 Accuracy 손실을 최소화하는 방법론을 제시합니다.
- BERT의 Fine-tuning 과정에서 Quantization-aware Training
- FC와 Embedding Layer 안에 있는 모든 GEMM (General Matrix Multiply) 연산을 Quantize함
- 8Bit Arithmetic과 GEMM에 최적화된 하드웨어를 사용
이 논문에서 만들어낸 방법론을 적용했을 때, 전체 모델의 99%에 해당하는 부분이 8Bit로 Quantize됨으로써 전체 모델 사이즈가 약 4배 정도 작아지게 되는 결과를 얻을 수 있습니다.
Method
이 단락에서는 이 논문에서 사용된 Quantization Scheme인 Linear Quantization과 Quantization-aware Training 방법론을 제시합니다. 이 방법론들을 취했을 때 Intel Xeon Cascade Lake의 VNNI (Vectorized Neural Network Instruction)이 지원되는 환경에서는 3.7배 정도 더 빨라지는 결과를 얻을 수 있었다고 합니다. 하지만 지정된 하드웨어를 사용하지 않아도 Intel의 MKL 등의 최적화 라이브러리를 사용하면 어느 정도의 속도 향상은 있을 것으로 보입니다.
Quantization Scheme
이 논문에서는 Symmetric Linear Quantization을 사용합니다. \(S^x\)가 Input \(x\)의 Quantization Scaling Factor일 때 다음과 같이 정의됩니다.
\[\text{Quantize}(x|S^x, M) := \text{Clamp}(\lfloor x \times S^x \rceil, -M, M), \\ \text{Clamp} (x, a, b) = \text{min}(\text{max}(x, a), b)\]단순하게 생각해서, \(x\)에 \(S^x\)를 곱해서 8Bit 표현 범위 이내로 Scale한 후 \(-M\)과 \(M\) 사이의 값을 지니도록 강제합니다. 여기서 \(M\)은 \(b\)개의 Bit를 사용했을 때 가질 수 있는 최대의 Quantized Value로, 다음과 같이 정의됩니다.
\[M = 2^{b-1} - 1\]즉, 만약 8Bit를 사용한다고 하면 \(M = 127\)이 되는 것입니다. Scaling Factor는 Inference 시에 동적으로 결정되거나 Training 중 수집된 통계 데이터를 통해서 계산될 수 있으며, Training 이후에 Calibration Set에서의 Inference를 하는 도중에 수집된 데이터로 계산할 수 있습니다.
Weight Scaling Factor \(S^W\)는 다음과 같이 계산됩니다.
\[S^W = \frac{M}{\text{max}(|W|)}\]또한, Activation Scaling Factor \(S^x\)는 EMA (Exponential Moving Average)를 이용해서 다음과 같이 계산됩니다.
\[S^x = \frac{M}{\text{EMA}(\text{max}(|x|))}\]Quantized-Aware Training
Quantization-aware Training은 NN을 학습시키면서 Quantization을 대비하는 방법론으로, Post-training Quantization과 대비되는 개념입니다.
이 논문에서는 Fake Quantization을 사용해서 모델이 학습 과정 중에 Quantization Error를 보면서 학습함으로써 Quantize된 환경에 적응할 수 있도록 도왔습니다.
Floating Point에 round() 함수를 적용하는 것과 비슷한데, Rounding Operation은 미분 가능하지 않으므로 STE (Straight-Through Estimnator)를 사용해서 다음과 같이 Gradient를 근사합니다.
Implementation
저자들은 BERT의 모든 Embedding Layer와 FC Layer들을 위 방법으로 Quantize하는 코드를 구현했습니다. Embedding Layer는 Fake Quantize가 수행된 Input을 반환하고 FC Layer는 Fake Quantize가 수행된 Input과 상기한 Scaling Factor들을 사용해서 GEMM을 수행합니다. Bias는 Int32로 Quantize되지만 이는 모델의 극히 작은 일부이기 때문에 무시할 수 있습니다.
전체적인 구현은 HuggingFace의 PyTorch-Transformers (지금은 transformers로 바뀌었습니다.)를 사용해서 이루어졌습니다.
상기한 변경이 그대로 들어갔고, 다만 높은 Precision을 요구하는 Softmax나 Layer Normalization, GELU 등은 FP32로 유지했습니다.
Evaluation
성능 평가에는 GLUE와 SQuAD를 사용했습니다.
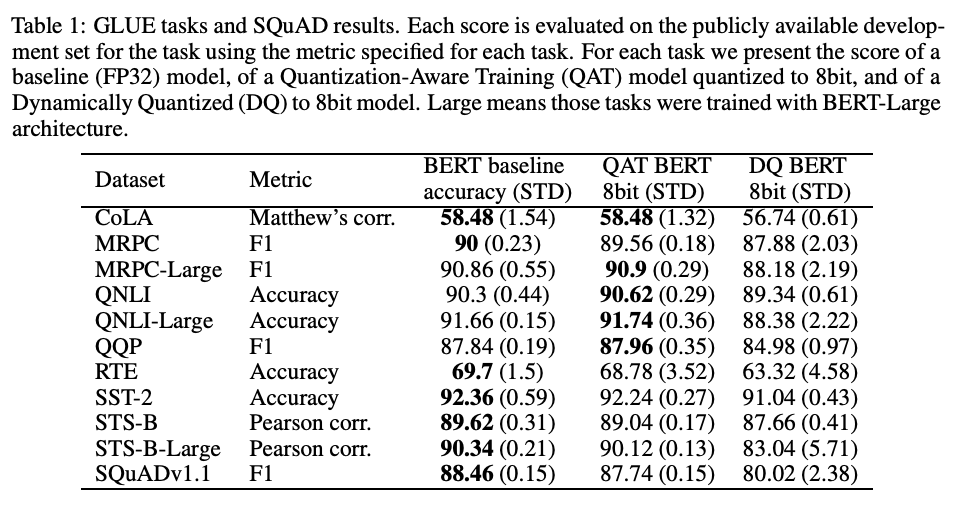
Dataset 및 Model 별 성능 평가 결과
대부분의 결과에서 원본 성능을 거의 유지했으며, 일부 모델의 경우 되려 더 나은 성능을 보인 것을 확인할 수 있습니다. Quantization에 의해 발생한 Error는 RTE를 제외하면 1%보다 낮은 수치를 보이고, 전체 모델의 Capacity는 4배 감소했습니다.
Effect of Quantization-Aware Training

Quantization-Aware Training의 효과 비교
Quantization-Aware Training의 효과를 비교해보기 위해서 일반적인 Dynamic Quantization (DQ) 방법과 Q8BERT의 방법을 비교한 표를 실었습니다. DQ 방법론이 확연이 드러나는 차이로 모든 Task에서 낮은 성능을 보이고 있음을 알 수 있습니다.
Related Work
- Transformer-LT
- Knowledge Distillation + 8Bit Post-Training Quantization
- Baseline Model 대비 BLEU Score가 1 낮아졌음
- Intel-specialized Hardware 사용한 버전도 있음
- Habana Labs
- 16Bit Quantize, 2배의 Compression 달성
- NVIDIA
- 추론 작업 시 Memory Bandwidth를 절약하는 여러 Optimized Kernel을 구현했음
- Sucik
- BERT를 Custom Dataset에서 Finetuning하고 이후 8Bit Post-training Quantization을 적용함
-
Previous
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices - Paper Review -
Next
프로그래머를 위한 파이썬 - Book Review