모바일 디바이스에서 추론할 수 있는 BERT를 만들고자 한 논문으로, ACL 2020에 소개되었습니다. BERT Large를 Pre-train한 후 이를 Teacher Model로 삼아 학습시켰을 때 BERT Base보다 4.3배 작고 5.5배 빠른 성능을 지녔습니다.
Introduction
NLP는 Pretraining Self-supervised Model을 기반으로 눈부신 발전을 했습니다. 그 선봉에는 BERT가 있었고, 많은 Task들에서 실질적인 Accuracy 향상이 있었습니다. 하지만, 지금까지 나왔던 모델들 중 가장 큰 모델답게, BERT는 굉장히 큰 모델 크기를 갖고 있고 추론하는데 시간이 오래 걸립니다. 이 점은 리소스가 제한된 모바일 디바이스에서의 추론을 거의 불가능하게 만듭니다.
지금까지 Distillation을 기반으로 하여 BERT의 크기를 줄이려는 다양한 시도들이 있었습니다.
- Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (Turc et al., 2019)
- 작은 규모의 BERT 모델을 Pre-train 함으로써 Task-specific Knowledge Distillation 성능 향상
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks (Tang et al., 2019)
- BERT를 Distill 해서 매우 작은 크기의 LSTM으로 만듦
- Patient Knowledge Distillation for BERT Model Compression (Sun et al., 2019)
- BERT에 Knowledge Distillation을 가해서 깊지 않은 Student 모델로 Transfer함
- Small and Practical BERT Models for Sequence Labeling (Tsai et al., 2019)
- Multilingual BERT에 Distill 해서 Sequence Labeling Task들을 푸는 작은 BERT 모델들로 만듦
하지만, 지금까지는 Task-agnostic Lightweight Pre-trained model을 만들려는 노력은 없었습니다. 기존의 BERT가 가지고 있던 강력한 장점인, 다양한 Task에 Fine-tune될 수 있는 형태는 없었습니다. MobileBERT는 이 간극을 채우기 위해 만들어졌습니다.
간단히 생각해보면, BERT를 Task-agnostic하고 Compact하게 가져가는 방법은 쉬울 것 같습니다. 그냥 BERT를 얇고 덜 깊게 만든 다음 Prediction Loss와 Distillation Loss 사이의 Convex Combination을 최소화하도록 훈련시키는 방법이 직관적일 것입니다. 하지만, 실험적인 결과로 보았을 때 이같은 직관적인 접근방법은 큰 Accuracy Loss를 기록했습니다.
MobileBERT는 BERT Large만큼 깊게 설계되었고, Bottleneck Structure를 도입하고 Self-attention과 Feed-forward Network 사이의 균형을 맞춤으로써 각 Layer를 훨씬 좁게 만들었습니다.
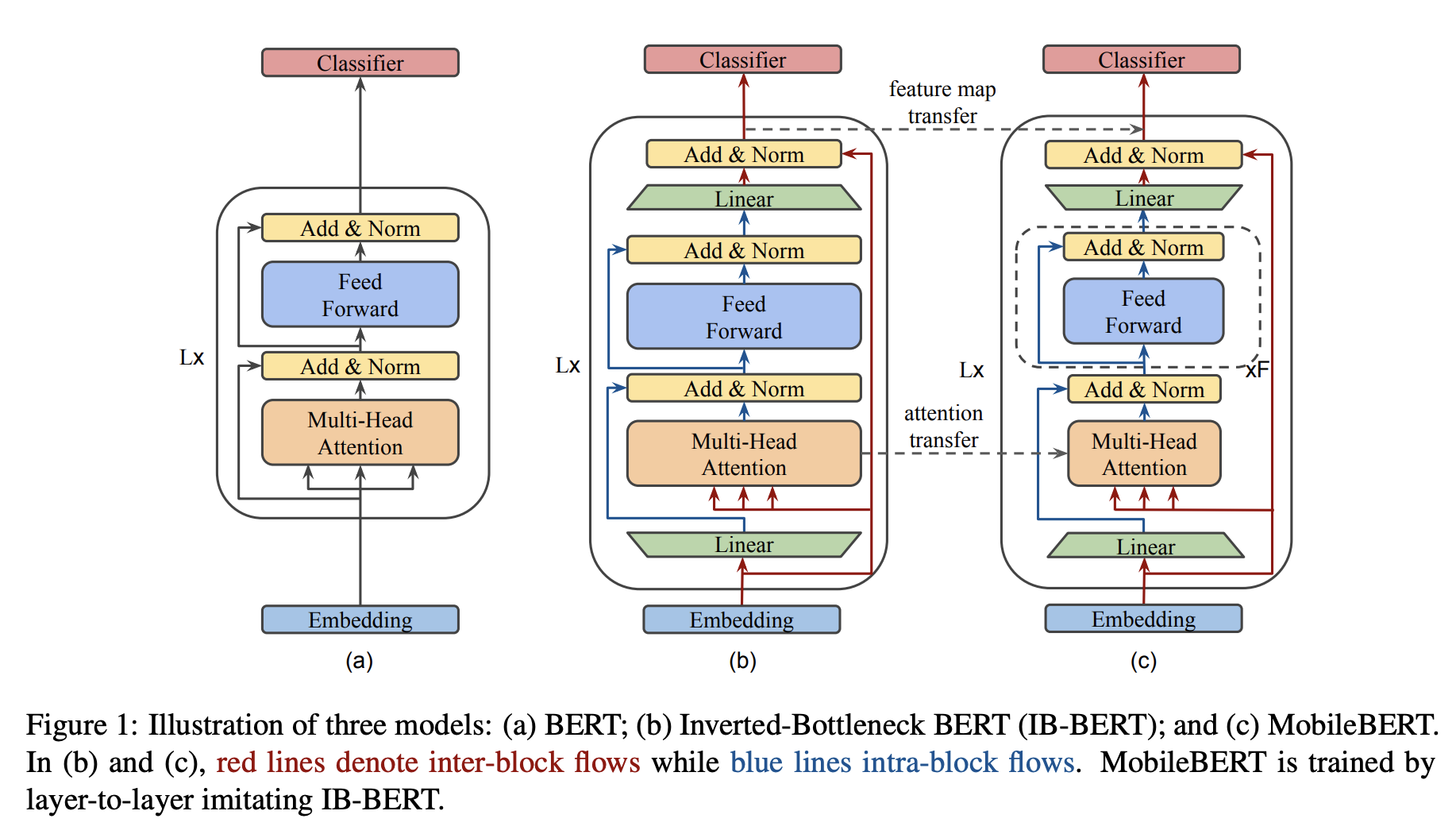
MobileBERT의 구조
MobileBERT를 훈련시키기 위해서는 먼저 Teacher Model을 훈련시켜야 합니다.
이 모델은 Inverted Bottleneck 구조를 사용한 BERT Large 모델로, IB-BERT라고 부릅니다. (b)
이 모델이 훈련된 뒤에는 MobileBERT로의 Knowledge Transfer를 진행해서 크기를 작게 만드는 방식입니다. (c)
이 구조를 바탕으로 실험해본 결과, MobileBERT는 \(\text{BERT}_\text{BASE}\)와 비교했을 때 비슷한 수준의 NLP Benchmark 결과를 내면서 4.3배 작고 5.5배 빠르게 추론했습니다. GLUE Benchmark를 돌려본 결과 GLUE Score 77.7을 기록했고, 이는 \(\text{BERT}_\text{BASE}\)보다 0.6 정도 작은 수치입니다. 이 모델은 Pixel 4 위에서 62ms의 추론 성능을 기록했습니다.
SQuAD v1.1/v2.0 에서는 Dev F1 Score 기준 90.3/80.2를 기록했으며, 이는 심지어 \(\text{BERT}_\text{BASE}\)보다 1.5/2.1 만큼 높은 수치입니다.
MobileBERT

MobileBERT Model Settings
Bottleneck and Inverted-Bottleneck
MobileBERT는 BERT Large 만큼 깊지만, 빌딩 블록 자체는 훨씬 작게 되어있습니다. 위 표에서 볼 수 있듯, Hidden Dimension은 128 밖에 되지 않습니다. (BERT Large는 1024를 갖습니다.)
또한, 각 블록마다 앞뒤로 Linear Transformation을 두어 입력과 출력 차원을 512로 조절하도록 했습니다. 이런 형식은 He et al., 2016에서 이야기했던 형식을 빌려 Bottleneck이라는 표현을 사용했습니다.
본래 깊고 얇은 네트워크를 성공적으로 훈련시키는 것은 어려운 일입니다. 논문에서는 우선 Teacher Network를 만들고 수렴할 때까지 훈련시킨 후, MobileBERT로의 Knowledge Transfer하는 방식으로 진행했다고 설명하고 있습니다. 이 방식은 MobileBERT를 아예 처음부터 훈련시키는 것보다 훨씬 나은 결과를 보였습니다.
조금 더 자세히 보자면, Teacher Network는 단순한 BERT Large에 Inverted Bottleneck 구조를 적용한 것입니다. Feature Map의 크기를 512로 고정시키기 위해서인데, 이렇게 할 경우 IB-BERT와 MobileBERT 사이에 같은 Feature Map Size를 공유하게 되고 Knowledge Transfer 전략 상 직접적인 비교가 가능해지게 됩니다.
이렇게 Bottleneck과 Inverted Bottleneck을 같이 사용하는 것은 굉장히 유연한 형태의 아키텍쳐 설계를 가능하게 합니다. 사실 한 쪽에만 사용해도 괜찮기는 합니다. MobileBERT의 Bottleneck을 BERT Large와 맞추는 용도로 사용하거나, IB-BERT의 Inverted Bottleneck은 MobileBERT에서 Bottleneck이 필요없게 하는 용도로 따로 사용하는 것이죠. 다만 함께 사용함으로써 IB-BERT Large가 성능을 보존하게 하고 동시에 MobileBERT가 충분히 Compact하게 줄어들 수 있게 합니다.
Stacked Feed-Forward Networks
이렇게 적용한 Bottleneck 구조는 한 가지 문제가 있었는데, 그건 Multi-Head Attention(MHA)과 Feed-Forward Network(FFN) 사이의 Balance가 맞지 않는다는 점입니다. 각각은 Transformer에서 다른 역할을 수행합니다. MHA는 다른 Subspace들 사이의 정보들을 Attend해주는 역할이고, FFN은 Model의 Non-linearity를 담당합니다.
원래 BERT에서의 MHA 대 FFN의 파라미터 크기 비율은 1:2였습니다. 하지만 Bottleneck Structure에서는 MHA의 입력이 더 넓은 Feature Map이고 FFN의 입력은 더 좁은 Bottleneck이기 때문에 MHA가 FFN보다 훨씬 더 많은 파라미터를 갖게 됩니다. 이 문제는 MHA 하나에 4개의 Stacked FFN을 뒤에 붙여줌으로써 다시 본래 비율을 잡아줌으로써 해결했습니다.
Operational Optimization
Model Latency를 분석해본 결과, Layer Normalization과 gelu Activation이 전체 지연 시간의 꽤 큰 부분을 차지함을 확인할 수 있었습니다.
MobileBERT에서는 이들을 대체할 다른 Operation들을 제안합니다.
Remove Layer Normalization
- n-channel Hidden State \(h\)에 대한 Layer Normalization을 제거
- 같은 크기의 Element-wise Linear Transformation으로 대체
- \(\gamma,\beta \in R^n\)이고, \(\circ\)는 Hadamard Product일 때 다음과 같음
Use relu Activation
geluActivation 대신 간단한reluActivation을 사용함
Embedding Factorization
BERT의 Embedding Table은 Model의 꽤 큰 부분을 차지합니다. 이 Embedding Layer를 압축하기 위해서, MobileBERT의 Embedding Dimension은 128로 줄어들었습니다. 그리고, Raw Token Embedding에 Kernel Size 3짜리 1D Convolution을 적용함으로써 512차원 크기의 결과를 출력하도록 했습니다.
Training Objectives
논문은 Feature Map Transfer, Attention Transfer의 두 가지 Knowledge Transfer Objective를 제시합니다. 또한 \(l^{th}\) Layer의 Layer-wise Knowledge Transfer Loss \(L^l_{KT}\)는 이 두 가지 Objective의 Linear Combination입니다.
Feature Map Transfer (FMT)
BERT의 각 Layer는 직전 Layer의 출력을 입력으로 받기 때문에, Layer-wise로 Knowledge Transfer를 할 경우 각 Layer의 Feature Map이 가능한 한 Teacher의 것과 비슷해야 합니다. 이 점에서 착안하여, FMT는 Teacher Model인 IB-BERT의 Feature Map과 MobileBERT의 Feature Map 사이의 Mean Squared Error(MSE)를 Objective로 삼습니다. \(l\)이 Layer Index, \(T\)는 Sequence Length, \(N\)이 Feature Map Size일 때 다음과 같습니다.
\[L^l_{FMT} = \frac{1}{TN} \sum^T_{t=1} \sum^N_{n=1} ( H^{tr}_{t,l,n} - H^{st}_{t,l,n} )^2 \qquad \cdots \qquad (2)\]Attention Transfer (AT)
Attention은 NLP 분야에서 성능을 확 끌어올린 대표적인 메커니즘이며, Transformer와 BERT의 중요한 빌딩 블록입니다. 그러므로, 잘 최적화된 Teacher Model의 Self-attention Map을 사용해서 MobileBERT를 학습시키면 높은 성능을 얻을 수 있을 것입니다. 이 점에서 착안하여, Teacher Model과 Student Model의 Per-Head Self-attention 분포 간의 KL-Divergence를 최소화하는 것을 Objective로 삼습니다. \(A\)가 Attention Head의 갯수일 때 다음과 같습니다.
\[L^l_{AT} = \frac{1}{TA} \sum^T_{t=1} \sum^A_{a=1} D_{KL}(a^{tr}_{t,l,a} \parallel a^{st}_{t,l,a}) \qquad \cdots \qquad (3)\]Pre-training Distillation (PD)
MobileBERT는 Layer-wise Knowledge Transfer 외에도 Knowledge Distillation Loss도 사용합니다. MLM Loss와 NSP Loss, 그리고 MLM Knowledge Distillation (KD) Loss를 Linear Combination한 것을 사용합니다. \(\alpha\)가 0 혹은 1인 Hyperparameter일 떄 다음과 같습니다.
\[L_{PD} = \alpha L_{MLM} + (1 - \alpha) L_{KD} + L_{NSP} \qquad \cdots \qquad (4)\]Training Strategies
위의 Objective들을 바탕으로, 다양한 조합의 학습 전략을 제시합니다. 이 논문에서는 총 세 가지를 소개하고 있습니다.
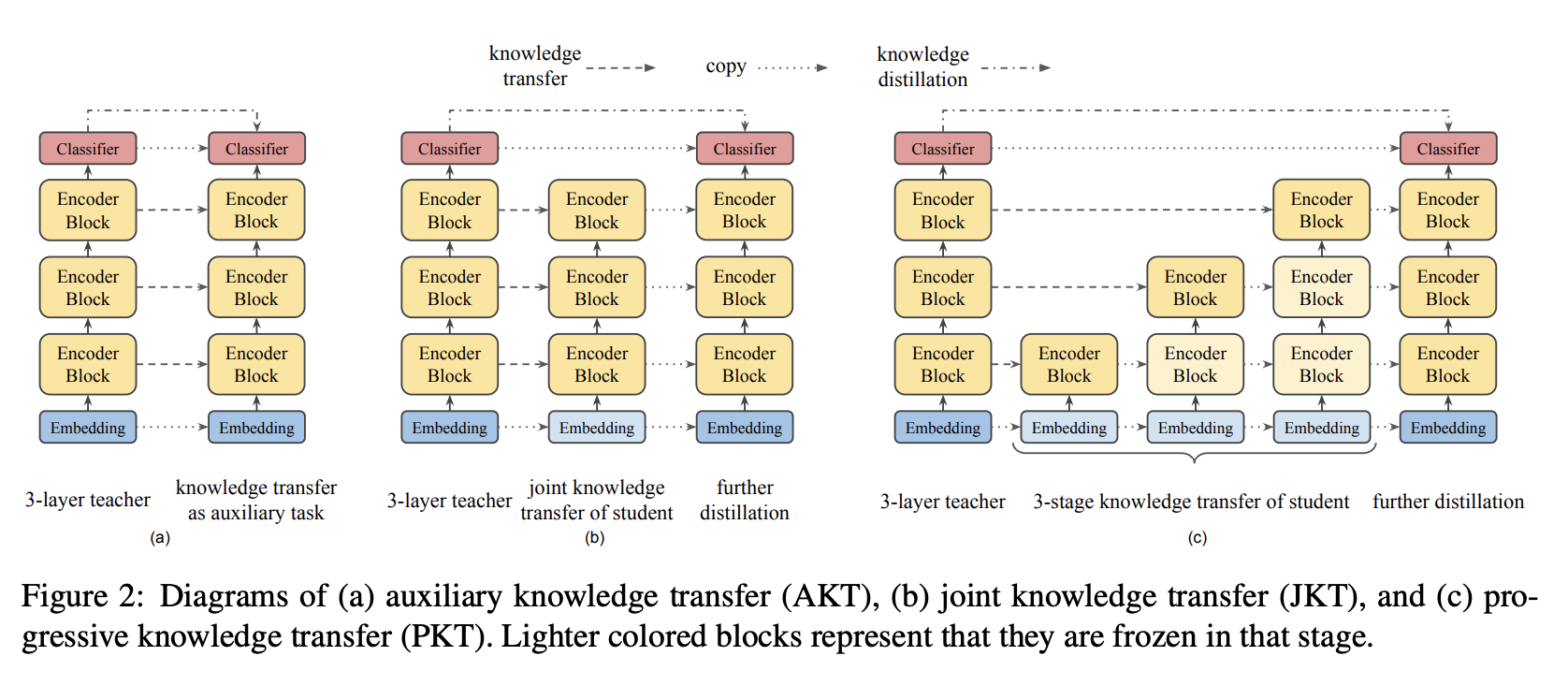
MobileBERT Training Strategies
Auxiliary Knowledge Transfer (AKT, a)
Intermediate Knowledge Transfer를 Knowledge Distillation의 Auxiliary Task로 보는 방식입니다. 모든 Layer의 Knowledge Transfer Loss의 Linear Combination을 Single Loss로 삼습니다. Pretraining Distillation Loss도 같은 기준을 적용받습니다.
Joint Knowledge Transfer (JKT, b)
IB-BERT Teacher Model의 Intermediate Knowledge는 MobileBERT Student에게 최적의 답이 아닐 수도 있습니다. 다른 구성을 지닌 모델이기 때문에 중간 단계 모델로 한 번 학습시킨 후 이를 이어받는 형식이 더 나을 수 있다는 논리입니다. 그래서 이를 2개의 다른 Loss Term으로 나누는 것을 제안하였는데, 다음의 두 과정을 거쳐 학습시킵니다.
- MobileBERT를 All Layer-wise Knowledge Transfer Loss로 학습시킴
- Pretraining Distillation으로 이를 다른 MobileBERT 모델에 한 번 더 학습시킴
Progressive Knowledge Transfer (PKT, c)
만약 MobileBERT가 IB-BERT Teacher를 완전히 복제받지 못했다고 치면, 낮은 레벨의 Layer에 있던 Error가 높은 레벨의 Layer에게 악영향을 미칠 수도 있습니다. 이 문제를 해결하기 위해서, Knowledge Transfer 과정에서 각 레이어를 점진적으로 학습시키는 방법을 제안하였습니다. 만약 \(L\)개의 Layer가 있다고 치면, 총 \(L\)개의 Tranining Stage가 있게 됩니다. \(l > 0\)인 \(l\) 번째 Layer를 학습하는 중에는 \(l\)보다 아래에 있는 모든 Layer를 Freeze한 상태에서 학습을 진행합니다.
Experiments
Model Settings
저자들은 우선 IB-BERT Teacher와 MobileBERT Student에 적합한 설정을 다양한 실험을 통해 찾았습니다. 성능의 기준은 SQuAD v1.1의 Dev F1 Score로 두었으며 각 Model을 125K Step + 2048 Batch Size로 학습시켰습니다.
Architecture Search: IB-BERT
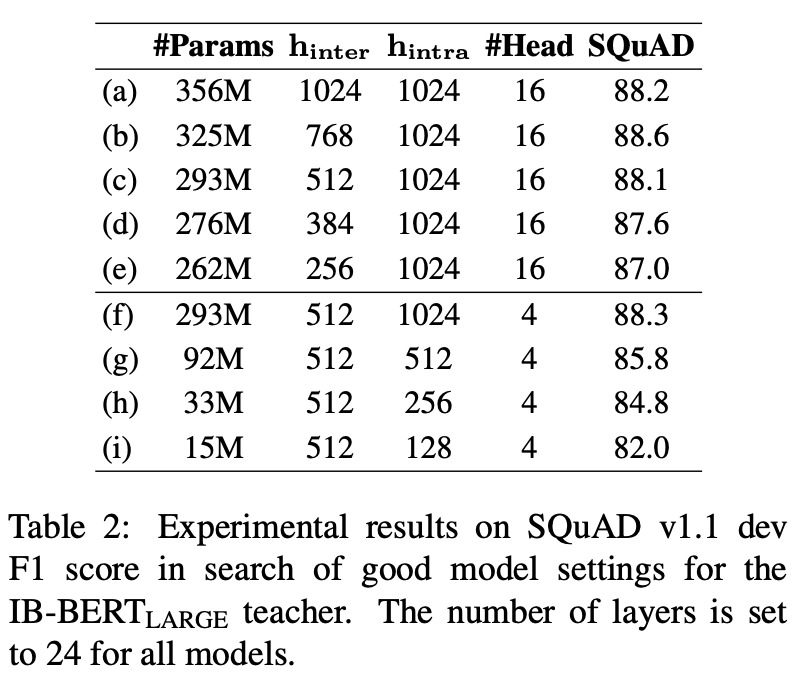
IB-BERT Architecture Search 결과
Teacher Model의 설계 철학은 최대한 Accuracy Loss를 없애면서 작은 Inter-block Hidden Size를 사용하는 것이었습니다.
이는 Feature Map의 크기를 작게 가져가겠다는 말과 동일합니다.
실험 결과, Inter-block Hidden Size는 512보다 작을 경우 BERT의 실제 성능에 영향을 끼치지 않는다는 것을 발견했습니다. (a부터 e까지의 실험 참조)
따라서 Teacher Model의 Hidden Size는 512로 설정하였습니다.
여기까지 보았다면 Intra-block Hidden Size를 줄일 경우에도 효과가 있을지를 의심해볼 수 있습니다.
이 실험 역시 진행하였으며, 그 결과 이 값을 줄이면 성능이 현격하게 낮아지는 것을 확인하였습니다. (f부터 i까지의 실험 참조)
이 값을 줄이는 건 Linear Module이 가지는 표현력 자체를 줄여버리는 것과 동일하기 때문에 BERT에서 상당히 중요한 역할을 하고 있는 값입니다.
따라서 Intra-block Hidden Size는 줄이지 않았습니다.
Architecture Search: MobileBERT
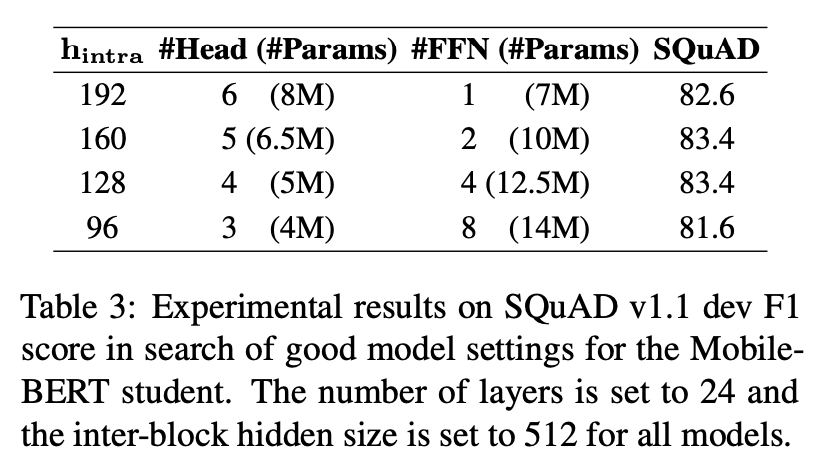
MobileBERT Architecture Search 결과
저자들은 BERT Base 기준 4배 정도의 압축 비율을 바탕으로 모델을 설계하고자 했고, 얼추 25M 정도의 Parameter를 지니되 MHA와 FFN의 비율을 달리 하는 방식으로 실험을 진행했습니다. 그 결과 가장 높은 성능이 나올 때의 MHA와 FFN 사이 비율은 0.4에서 0.6 사이였습니다. 본래 Transformer가 취했던 Parameter Ratio인 0.5와 상당히 근접한 수치입니다.
저자들은 128의 Intra-block Hidden Size와 네 겹으로 쌓아올린 FFN을 취한 모델을 선택했습니다.
이를 바탕으로 Layer-wise Knowledge Transfer를 위해 Teacher Model의 Attention Head 갯수 또한 4로 설정했습니다.
이 변경은 자칫 Teacher Model의 성능을 감소시킬 수도 있다는 우려가 있으나, 위의 IB-BERT 실험 결과에서 a와 f를 비교해보면 성능 손실이 없었음을 확인할 수 있습니다.
Implemention Details
BERT와 동일하게 BooksCorpus와 English Wikipedia를 Pre-training Data로 사용했습니다. IB-BERT Large를 256개의 TPUv3 칩 위에서 LAMB Optimizer로 학습시켰고 원래 BERT와의 비교를 위해서 아무런 Training Trick을 사용하지 않았습니다.
Downstream Task의 경우, 모든 결과는 BERT에서와 똑같이 단순히 MobileBERT를 각 Task에 대해서 Fine-tuning한 결과입니다.
Results on GLUE
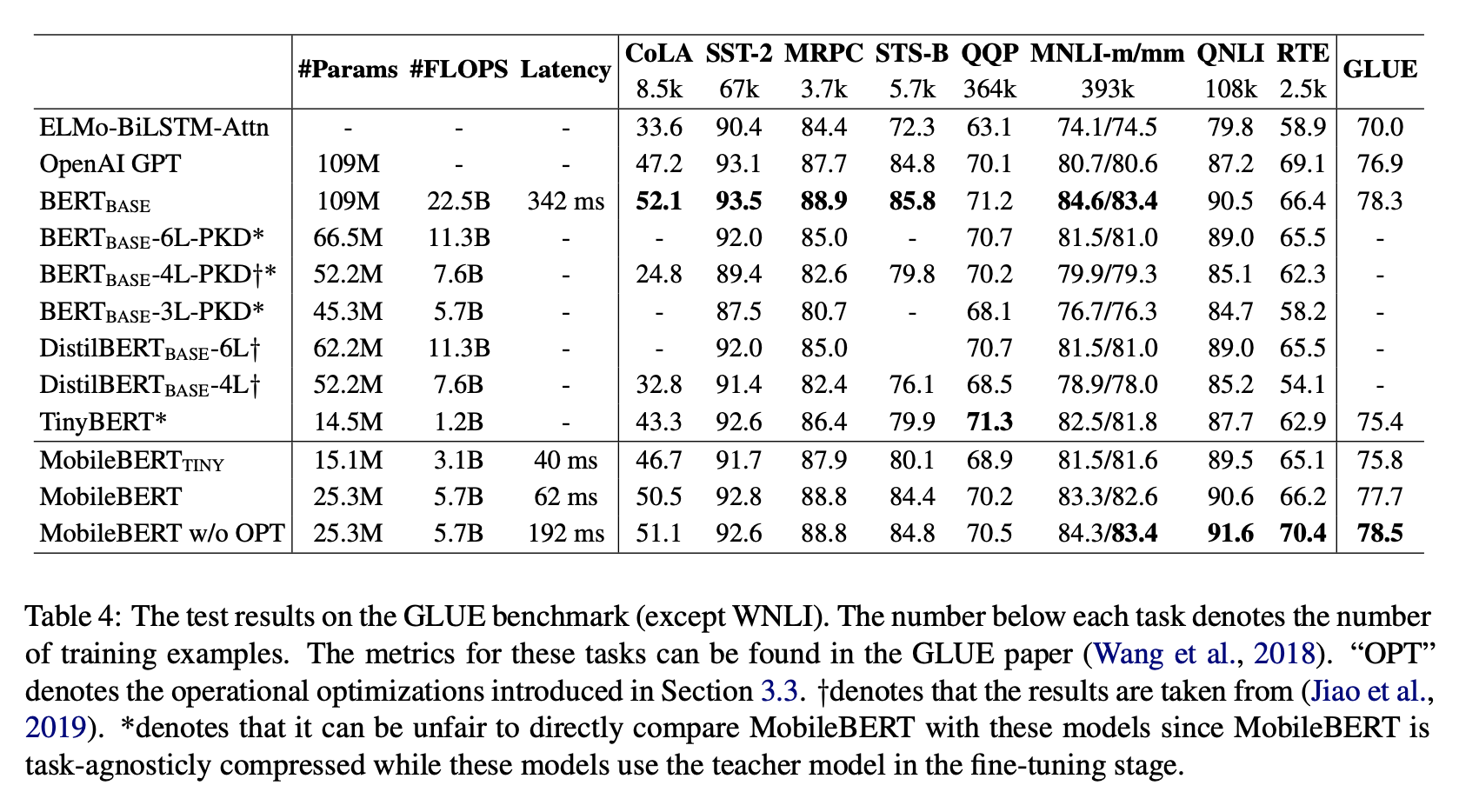
GLUE Benchmark 결과 표
ELMo와 GPT, BERT Base, DistilBERT, TinyBERT를 비교군으로 삼았습니다. MobileBERT는 Overall GLUE Score 기준 77.7을 달성했으며, 이는 BERT Base와 비교했을 때 0.6 밖에 적지 않은 수치입니다. 이와 동시에, BERT Base보다 4.3배 적은 Parameter를 가졌으며 5.5배 더 빠르게 추론했음을 볼 수 있습니다.
여기에서 MobileBERT Tiny는 FFN의 갯수를 줄이고 더 가벼운 MHA를 사용한 버전입니다. 실제로 4 스레드 Pixel 4에서 TensorFlow Lite 구현체로 실행한 결과 40ms 라는 추론 속도를 볼 수 있었습니다.
Results on SQuAD
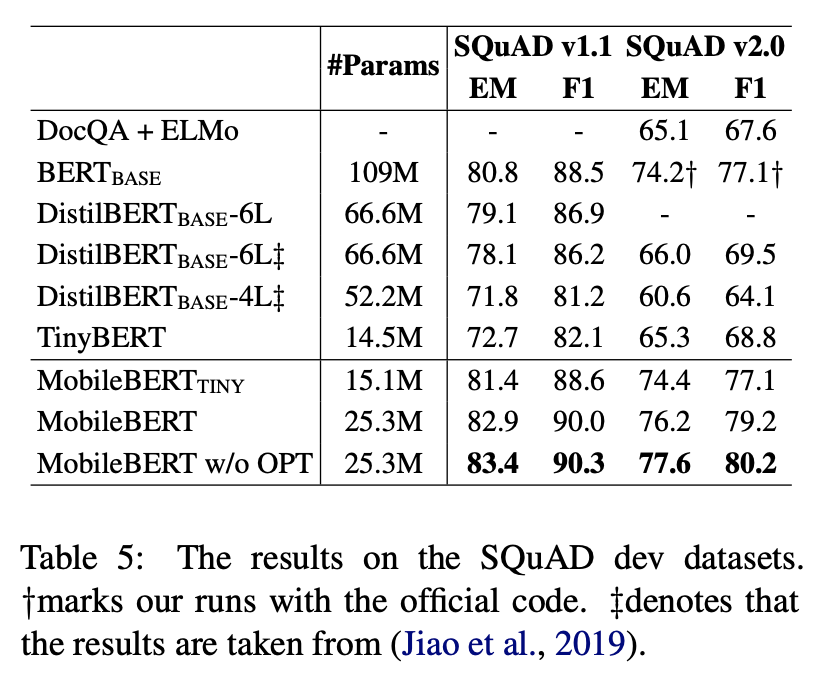
SQuAD 결과 표
MobileBERT는 비슷한 크기의 모든 모델들을 큰 차이를 두며 앞섰습니다.
Quantization
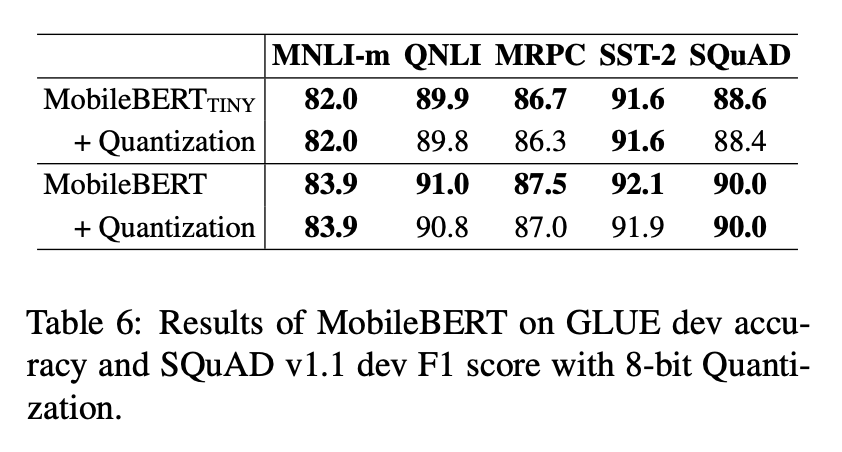
Quantization 결과 표
저자들은 일반적인 Post-training Quantization을 부여했고 4배 가량 더 압축할 수 있었습니다. 하지만 성능 하락이 거의 없었으며, 이는 아직 MobileBERT의 압축이 훨씬 더 많이 가능하다는 것을 암시합니다.
Ablation Studies
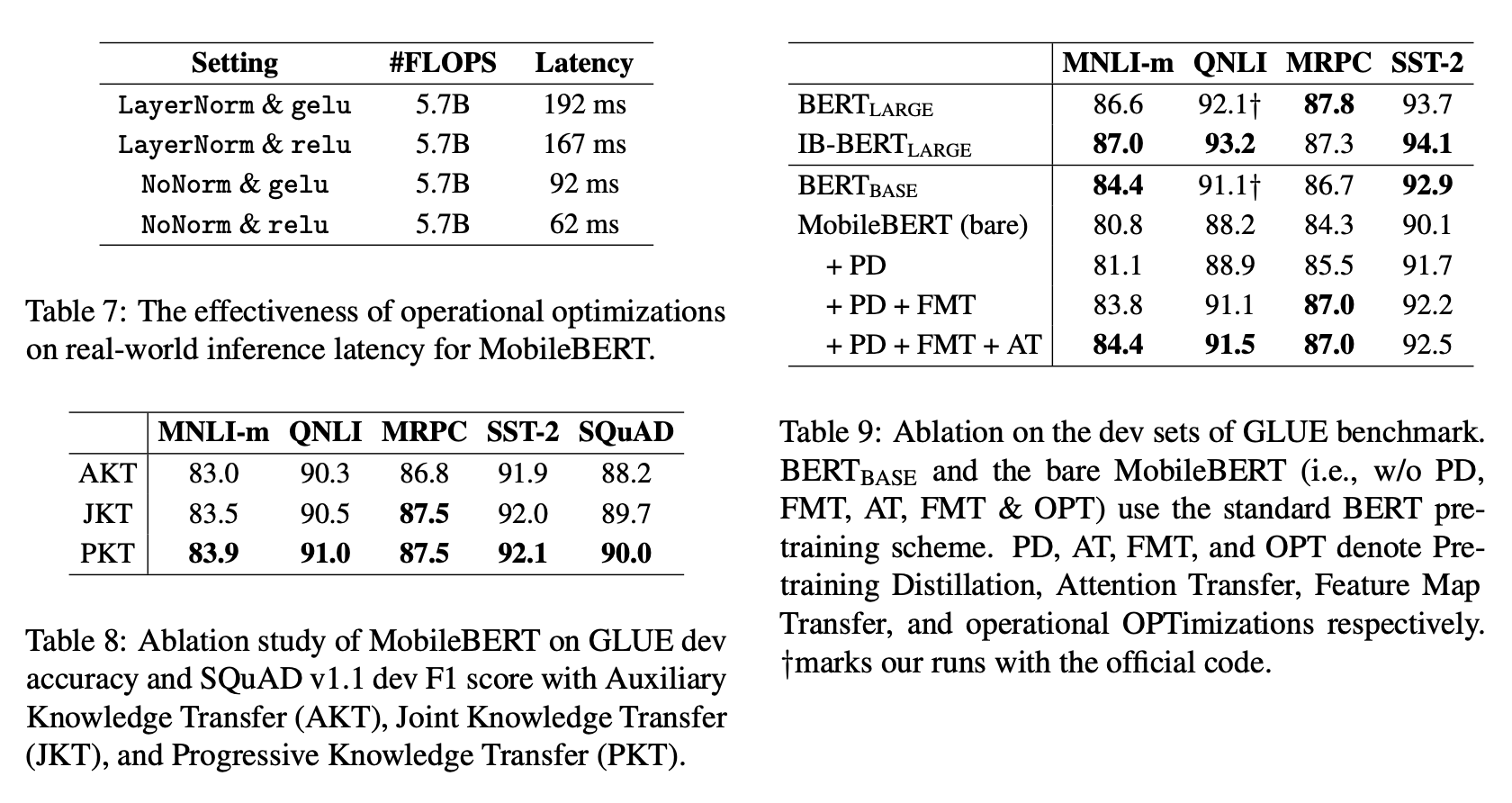
Ablation Studies
Operational Optimizations (Table 7)
Layer Normalization과 gelu를 사용하지 않고 NoNorm과 relu를 사용한 것에 대해서, 각각 FLOPS와 Latency를 조사했습니다.
그 결과, NoNorm과 relu를 사용하는 것이 FLOPS를 낮추지 않은 채로 Latency를 크게 줄이는 것을 확인할 수 있었습니다.
Training Strategies (Table 8)
앞서 소개했던 세 가지의 전략인 AKT, JKT, PKT를 GLUE의 Fine-tuning Task들을 기반으로 비교하였습니다. 그 결과 모든 Task에서 Progressive Knowledge Transfer 방식이 가장 성능이 좋았습니다. 저자들은 그 이유로 Teacher의 Intermediate Layer-wise Knowledge가 Student에게 잘 맞지 않았던 것이기 때문에 추가적인 Pre-training Distillation Stage가 필요했던 것이 아니었냐고 분석했습니다.
Training Objectives (Table 9)
역시 앞서 소개했던 AT, FMT, PD와 Operational Optimizations (OPT)에 대해서 GLUE의 Fine-tuning Task들을 기반으로 비교하였습니다. 그 결과 FMT가 성능에 굉장히 큰 기여를 하고 있음을 발견하였으며, 나머지인 AT와 PD도 긍정적인 변화를 주고 있음을 확인했습니다. 또한, IB-BERT Large가 충분히 강력하고 MobileBERT가 성능을 크게 깎아내렸다는 것을 보았을 때 아직 최적화할 거리가 많이 남아있음을 암시한다고 분석했습니다.
Conclusion
이 논문은 특정 Task에 Fine-tuning할 수 있는, BERT의 Compact한 변종인 MobileBERT를 제시했습니다. 실험적으로 이 모델이 BERT Base에 준하는 수준의 성능을 지니면서 동시에 작고 빠르게 동작하는 점을 증명했습니다. 이 점은 여러가지 NLP Application들을 모바일 디바이스에 쉽게 배포할 수 있도록 해줄 것입니다.