BERT나 RoBERTa와 같이 사전 학습된 Language Model들은 많은 NLP Task에서 좋은 성능을 보이지만 그만큼 연산량이 많고 메모리 비용이 큽니다. 이 논문에서는 Width와 Depth를 Adaptive하게 조절할 수 있는 형태의 BERT Model을 소개합니다.
Abstract
BERT의 크기를 줄이기 위한 최근의 Approach에서는 특정 Task를 노리고 압축하는 형태의 방법론이 있었습니다. 하지만 최근의 BERT 압축 방법들은 큰 BERT 모델을 단순히 고정된 작은 사이즈로 줄이기만 하고, 여러 Hardware Performance를 가진 Edge Device에서의 요구 조건을 만족하지는 못했습니다.
DynaBERT는 Width와 Depth를 조절하여 트레이닝할 수 있게 하는 형태의 모델입니다. 일단 Width-adaptive하게 트레이닝하고, 그 후에 Depth까지 전부 학습시킴으로써 큰 사이즈의 모델에서 조그만 Subnetwork에 Knowledge Distillation을 가할 수 있도록 합니다.
이 과정에서 Network rewiring을 사용해서 더 중요한 Attention Head들과 Neuron들을 더 많은 Subnetwork에서 사용할 수 있도록 했습니다.
Introduction
BERT를 Edge Device에 배포하는 것은 크게 두 가지 관점에서 어렵습니다.
- Device마다 Hardware Performance가 다르기 때문에 하나의 BERT 모델을 여러 Edge Device에 배포하는 것이 불가능함
- 하나의 Device에서의 Resource Condition이 상황에 따라 천차만별일 수 있음
지금까지 Transformer를 기반으로 한 모델들을 압축하거나 추론을 가속하려는 많은 형태의 시도가 있었습니다. 하지만 이런 방법들은 보통 모델을 고정된 특정 사이즈로 압축하고, 위 관점에서의 요구 사항을 만족하지 못합니다.
Transformer 기반의 모델에서 Adaptive Depth를 지원하도록 하는 논문이 있었습니다. 그러나, 이 논문 역시 Depth 방향으로의 압축과 추론 가속화만을 다루었습니다. 최근의 연구들은 모델이 Width 방향으로도 높은 반복성을 갖는다고 말하고 있습니다. 예를 들면, Attention Head를 조금 적게 써도 비교할 만한 수준의 Accuracy가 나왔다는 것이 증명되었습니다.
CNN에서 Adaptive Width를 적용한 형태의 연구가 있었습니다만, CNN과 비교하면 BERT는 훨씬 복잡한 형태이기 때문에 이 연구 내용을 그대로 활용하지 못합니다. Multi-Head Attention이나 Feed Forward Network에의 최적화 때문에 CNN의 Kernel Width 조절과 같은 간략한 방법을 그대로 활용하기는 어렵습니다.
이 논문에서는 Width와 Depth 모두에서 유연함을 제공할 수 있는 형태의 Dynamic BERT, 줄여서 DynaBERT를 소개합니다. DynaBERT는 우선 Width-adaptive한 BERT를 학습시킵니다. (줄여서 \(\text{DynaBERT}_{W}\)) 그 이후에 Width와 Depth 모두 Adaptive하게 학습하도록 합니다.
Width-adaptive한 모델을 학습하기 위해 우선 각 Transformer Layer의 연결들을 Rewire합니다. 이 작업의 목적은 더 중요한 Head들과 Neuron들이 Subnetwork에 의해서 더욱 잘 사용될 수 있도록 중요도에 따라 역할을 조정해주기 위함입니다. 그 이후에 Teacher Network으로부터 Distill해서 조금 더 작은 가로 길이를 가진 모델로 지식을 투영합니다.
이 모델이 모두 학습된 이후에, 모델의 Weight를 이용해서 진짜 \(\text{DynaBERT}\) 의 Weight를 초기화합니다. Width 방향으로 이미 배운 유연성을 잃지 않기 위해서 Width와 Depth 방향 모두에 Knowledge Distillation을 사용합니다.
BERT Base와 RoBERTa Base를 각각 Backbone으로 하여 실험해본 결과, 모두 원본 모델과 비교할 만한 성능을 얻을 수 있었습니다.
Related Work
Transformer Layer
BERT는 Self Attention을 통해 Long-Term Dependency를 잡아낼 수 있는 Transformer Encoder Layer를 사용하여 구성되었습니다. 표준 Transformer Layer는 Multi-Head Attention과 Feed-Forward Network를 가지고 있습니다.
FFN Layer에서는 \(W_1\)과 \(W_2\), 2개의 Weight를 사용하며 중간에 Activation으로 GELU를 사용합니다.
Compression for Transformer/BERT
Transformer 기반의 모델은 아래의 5가지 방법으로 압축될 수 있습니다. 하지만 이 방법들은 여러 Hardware들과 여러 상황들에 대한 고려가 빠진 방법들입니다.
Low-rank Approximation
Weight Matrix를 작은 차원의 두 행렬의 곱으로 근사(Approximate)합니다.
- ALBERT는 Word Embedding에 사용했습니다.
- Tensorized Transformer는 Multi-Head Attention의 결과가 서로 직교하는 Base Vector의 그룹으로 표현될 수 있음을 보였습니다.
Weight Sharing
Weight Parameter를 하나의 네트워크 안의 여러 Layer들 사이에 공유합니다.
- Universal Transformer는 Weight을 여러 Layer들 사이에 공유하는 방식을 사용해 Language Modeling과 Subject-Verb Agreement에서 표준 Transformer보다 더 나은 성능을 보였습니다.
- ALBERT는 Layer들 사이에 Weight을 공유시켜 Network Parameter를 안정화했고, BERT보다 더 적은 Parameter들로 더 나은 Performance를 보였습니다.
Distillation
큰 Teacher Model에서 작은 모델로 지식을 전달합니다.
- DistilBERT는 작은 범용 BERT를 Soft Logit에 대해 Distillation Loss를 사용해 Pre-training했습니다.
- BERT-PKD는 여러 개의 중간 Layer에 Distillation Loss를 사용했습니다.
- TinyBERT는 Embedding과 Attention 배열 요소들, Transformer Layer의 각 Output에 General Distillation과 Task-specific Distillation을 성공적으로 사용하여 특정 Task에 대한 작은 모델을 만들었습니다.
Quantization
각 Weight Value를 더 작은 수의 비트로 표현합니다.
- QBERT는 각 Layer의 비트 갯수를 결정하기 위해 Second-order Information을 사용했고, 더 많은 비트들을 더 깊은 곡면을 가지는 레이어에 더했습니다.
- Fully-quantized Transformer는 비싼 연산들에 대해서 Uniform Min-Max Quantization을 사용했습니다.
- Q8BERT는 Quantization-aware Training을 통해 BERT에 대칭형 8-bit Linear Quantization을 가했습니다.
Pruning
네트워크에서 중요하지 않은 Connection들이나 Neuron들을 걸러냅니다.
- Pruning Convolutional Neural Networks for Resource Efficient Inference에서, Pre-training에 Magnitude-based Pruning Method가 사용되었습니다.
- Fine-tune BERT with sparse self-attention mechanism에서는 Fine-tuning 중 Softmax를 Controllable Sparse Transformation으로 전환하는 형태의 Sparse Self-Attention이 소개되었습니다.
- Pruning a BERT-based Question Answering Model에서는 각 요소에 Gate를 만들어 각각 Transformer 구조에서 제외할 수 있도록 만들었습니다.
- LayerDrop에서는 보다 더 효율적인 추론을 위해 Structured Dropout을 사용하여 Transformer Layer를 정리했습니다.
- Depth-Adaptive Transformer에서는 특정 Sequence가 Encoder-Decoder Transformer 모델이 Decoder의 다른 레이어에서 Output Prediction을 만들어내도록 훈련하였습니다.
Method
Training \(\text{DynaBERT}_{W}\) with Adaptive Width
우선 BERT의 Width를 결정해야 하는데, CNN과 비교했을 때 Transformer 모델은 Multi-Head Attention이나 Feed-Forward Network 등 훨씬 복잡한 형태를 취하고 있기 때문에 쉽게 결정할 수 없습니다.
Using Attention Heads and Intermediate Neurons in FFN to Adapt the Width
\[\text{MHAttn}_{W^Q, W^K, W^V, W^O} (X) = \sum^{N_H}_{h = 1}\text{Attn}^{h}_{W^{Q}_{h}, W^{K}_{h}, W^{V}_{h}, W^{O}_{h}}(X)\]그래서 우선 위와 같이 MHA의 계산을 각 Attention Head의 계산으로 나누었습니다. Attention Head의 갯수에 따라 MHA의 Width가 정해지도록 설정할 수 있습니다.
각각의 Transformer Layer에서, Width Multiplier가 \(m_w\)일 때 다음과 같이 Width를 줄입니다.
- MHA는 왼쪽부터 \(\lfloor m_wN_H \rfloor\) 개 만큼의 Attention Head를 가집니다.
- FFN Intermediate Layer는 왼쪽부터 \(\lfloor m_w d_{ff} \rfloor\) 개의 Neuron을 가집니다.
이렇게 처리하면 얼추 \(m_w\) 정도의 비율로 압축하게 됩니다.
다른 Transformer Layer나 Attention Head, Neuron은 다른 Width Multiplier를 가질 수 있습니다. 이 논문에서는 모든 경우에 대해 하나의 Multiplier를 사용했습니다.
Network Rewiring
전체 네트워크가 가질 크기를 최대한 활용하기 위해, 더 중요한 Head들과 Neuron들은 여러 Subnetwork 사이에 공유되어야 합니다. 이 논문은 원래 BERT 모델에서의 중요도에 기반해서 Attention Head들과 Neuron들의 중요도 순서를 매깁니다.

Network Rewiring Algorithm
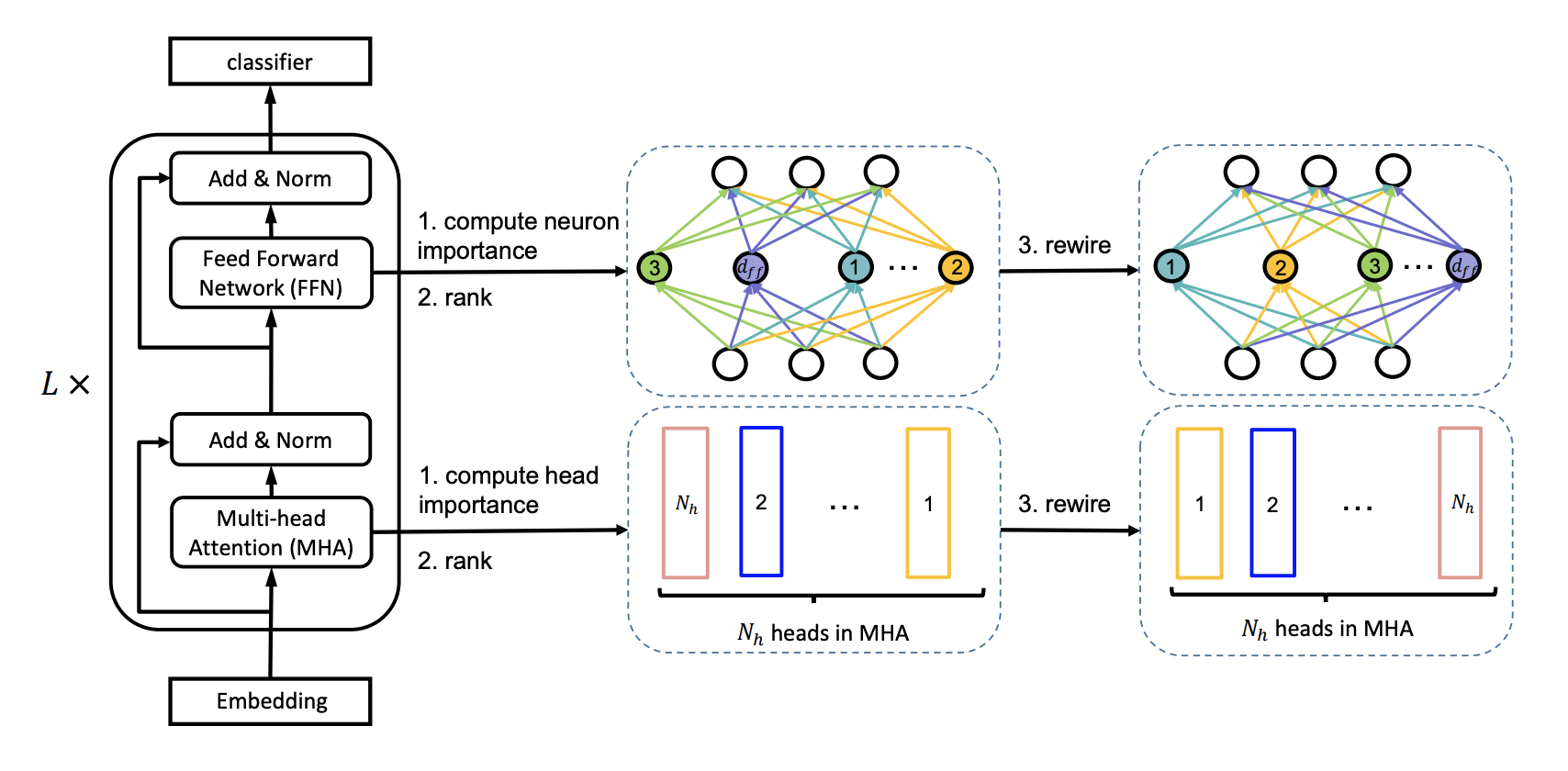
Network Rewiring 모식도
Training with Adaptive Width
Rewiring을 마친 뒤에, \(\text{DynaBERT}_W\)를 훈련시키기 위해 Knowledge Distillation을 사용합니다. Rewire된 BERT 모델을 Fixed Teacher Model로 사용하고, 동시에 \(\text{DynaBERT}_W\)를 초기화하는데도 사용합니다.
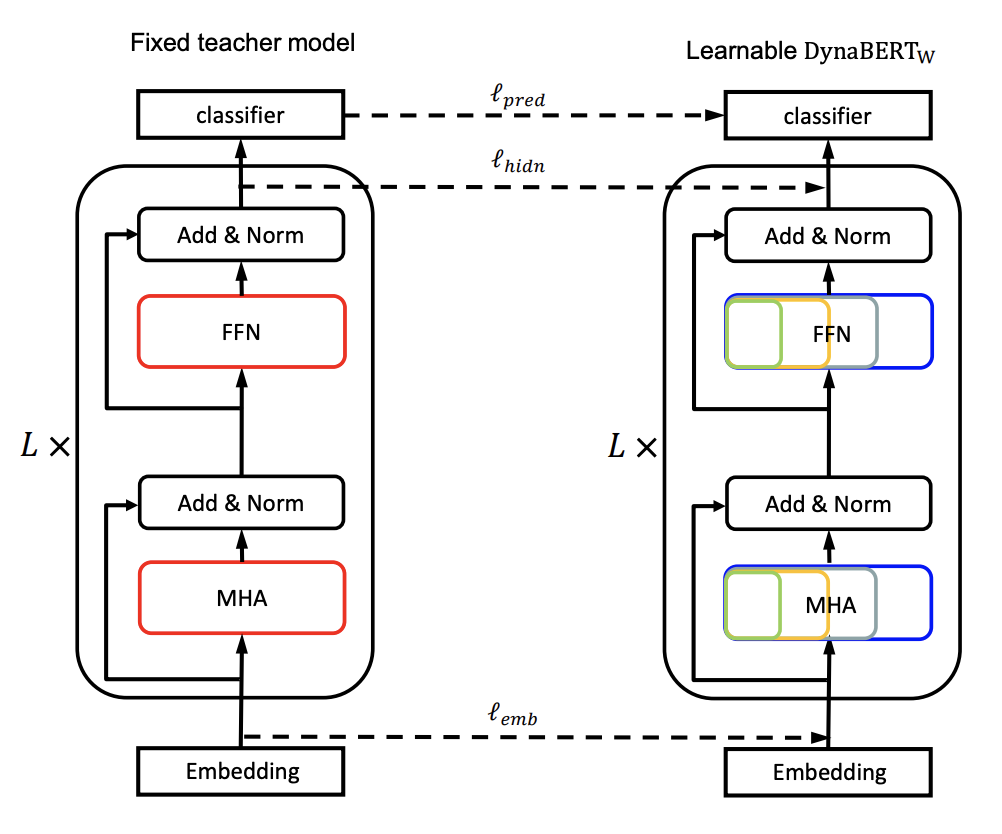
Knowledge Distillation
Classification Task를 예로 들면, Logit, Embedding, Hidden State를 각각 Student Subnetwork로 Distillation해야 합니다. Distillation Loss Function은 세 부분으로 나뉘어집니다.
첫 번째는 Logit Loss \(l_{pred}\)에 대한 계산으로, Soft Cross-Entropy Loss를 통해 Distillation합니다.
\[l_{pred}(y^{(m_w)}, y) = - \text{softmax} (y) \cdot \text{log\_softmax} (y^{(m_w)})\]두 번째는 Embedding Loss \(l_{emb}\)에 대한 계산으로, Teacher 모델의 Embedding을 MSE를 통해 Distillation합니다.
\[l_{emb}(E^{(m_w)}, E) = \text{MSE}(E^{(m_w)}, E)\]마지막으로, Hidden State Loss \(l_{hidn}\)에 대해 계산합니다. Student Model의 각 Transformer Layer가 Teacher 모델의 대응되는 Layer의 Output을 그대로 따라하도록 학습시킵니다.
\[l_{hidn}(H^{(m_w)}, H) = \sum^L_{l=1} \text{MSE} (H_l^{(m_w)},H_l )\]위의 세 식을 합치면, \(\lambda_1, \lambda_2\)가 각각 다른 Loss Term의 Weight에 대한 Scaling Parameter라고 할 때 목적 함수 \(L\)은
\[L = \lambda_1 l_{pred}(y^{(m_w)}, y) + \lambda_2 l_{emb}(E^{(m_w)}, E) + l_{hidn}(H^{(m_w)}, H)\]와 같이 됩니다. 논문에서는 \((\lambda_1, \lambda_2) = (1, 0.1)\) 으로 사용했습니다.

Adaptive Width Training Algorithm
Training DynaBERT with Adaptive Width and Depth
위에 기술한 대로 Width-adaptive한 모델을 학습시킨 뒤에, Knowledge Distillation을 활용해서 Depth-adaptive까지 추가된 DynaBERT를 학습시킵니다. 여기서 Teacher Model로 사용되는 것은 방금 학습시킨 \(\text{DynaBERT}_W\)입니다. 역시 초기화에도 사용합니다.
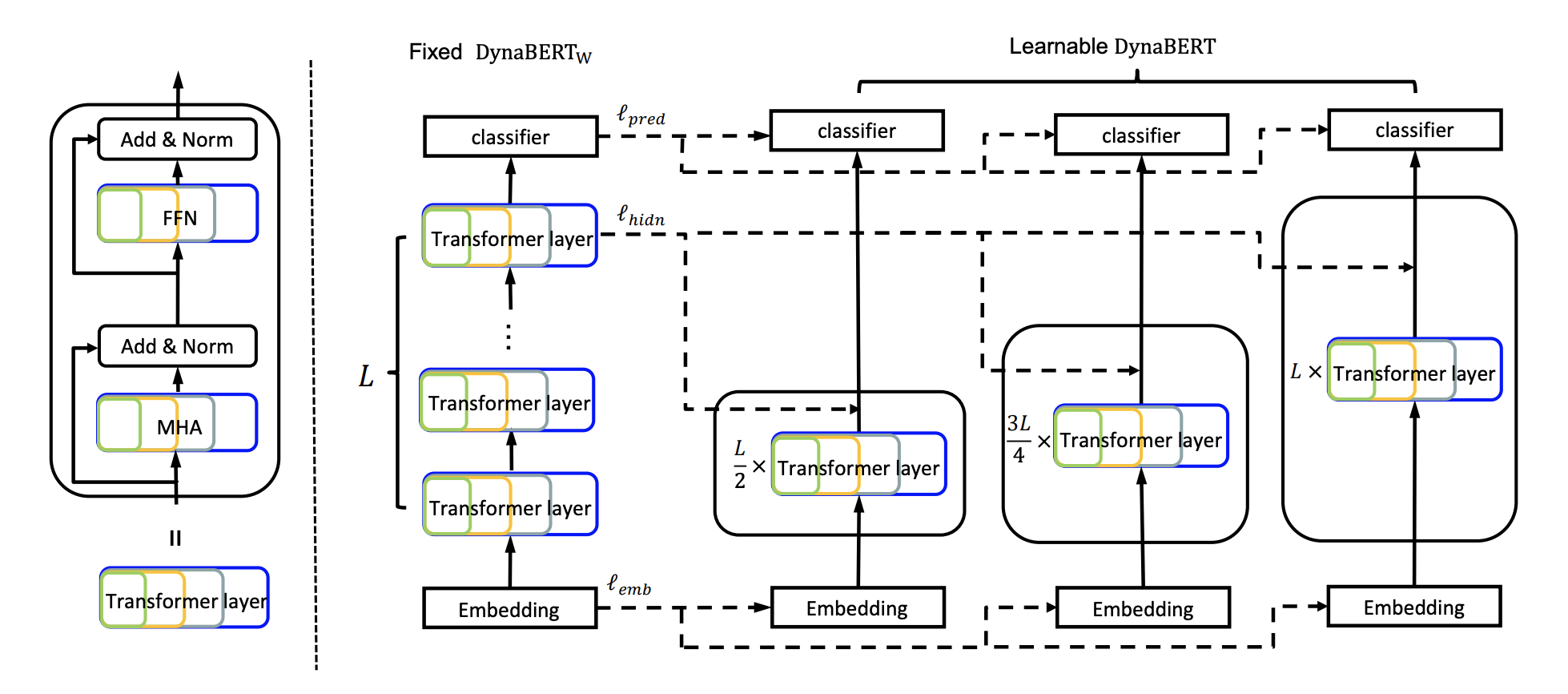
Training DynaBERT: Knowledge Distillation
모델 학습 중 배운 Width 방향에 대한 유연성에 Catastrophic Forgetting이 작용하는 것을 막기 위해서, 반복마다 여러 Width에 대해서 훈련시킵니다. Loss는 전 단계와 비슷하게 세 부분으로 구성되는데, 역시 Logit, Embedding, Hidden State가 Teacher Model을 따라가도록 구성합니다. 여기에서 Depth Multiplier \(m_d\)를 사용하는데, 이 값이 1보다 작을 경우 Teacher Model보다 더 작은 수의 Transformer Layer를 가지게 됩니다. 이 경우에는 Depth Multiplier \(m_d\)에 대하여, \(mod(d + 1, \frac1m_d)\) 번째 레이어들을 Drop합니다. 예를 들어, 12개의 Layer로 이루어진 BERT에 \(m_d = 0.75\)가 부여되었다면, 3, 7, 11번 레이어를 삭제하게 됩니다. Loss는 삭제된 레이어를 제외한 나머지 레이어에 대해서만 계산됩니다.
따라서 DynaBERT의 목적 함수는 다음과 같습니다.
\[L = \lambda_1 l_{pred} ( y^{ (m_w, m_d) }, y^{ (m_w) } ) + \lambda_2 l_{emb} ( E^{ (m_w, m_d) }, E^{ (m_w) } ) + l_{hidn} ( H^{ (m_w, m_d) }, H^{ (m_w) } )\]논문에서는 \((\lambda_1, \lambda_2) = (1, 1)\) 으로 사용했습니다.

Algorithm for Training DynaBERT
Experiment
Setting
DynaBERT, DynaRoBERTa를 각각 BERT Base, RoBERTa Base와 비교합니다. 아래는 사용한 Hyperparameter입니다.
- Transformer Layers \(L = 12\)
- Hidden State Size \(d = 768\)
- MHA Number of Heads \(N_H = 12\)
- FFN Number of Neurons \(d_{ff} = 3072\)
- Width Multiplier \(m_w = [1.0, 0.75, 0.5, 0.25]\)
- Depth Multiplier \(m_d = [1.0, 0.75, 0.5]\)
- Width와 Depth를 합해서 총 12개의 Configuration이 존재합니다.
Main Results
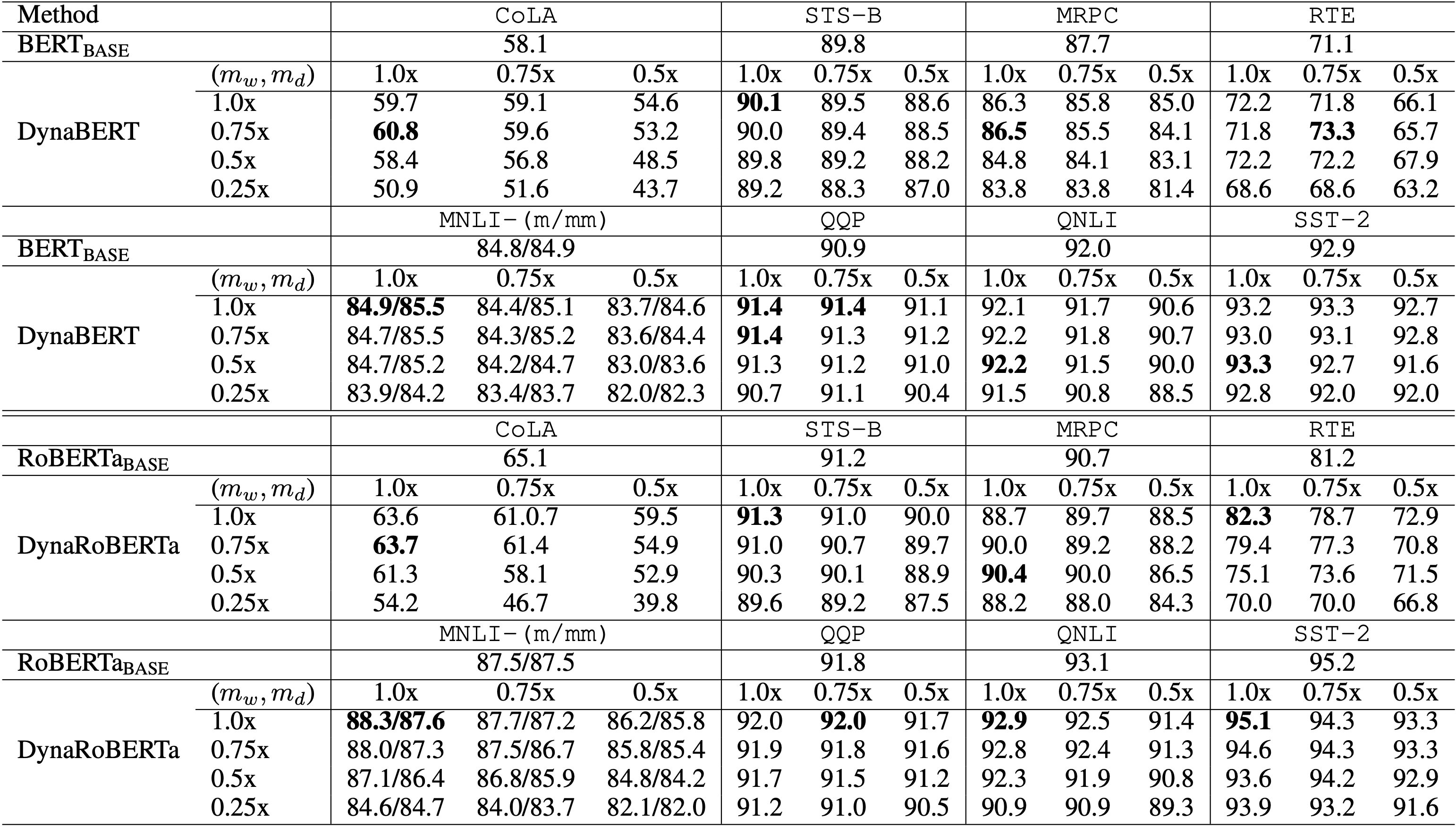
실험 결과
Multiplier가 \((m_w, m_d) = [1.0, 1.0]\)로 설정된 부분에서는 다소 앞선 결과들도 있었으나 어차피 같은 사이즈의 모델이므로 이는 큰 의미가 없어보입니다. 다만 0.75 ~ 0.5 대역에서도 비슷하거나 더 높은 성과를 보이는 Task가 발견되며, 성능 손실이 있더라도 얼마 안되는 것을 확인할 수 있습니다.
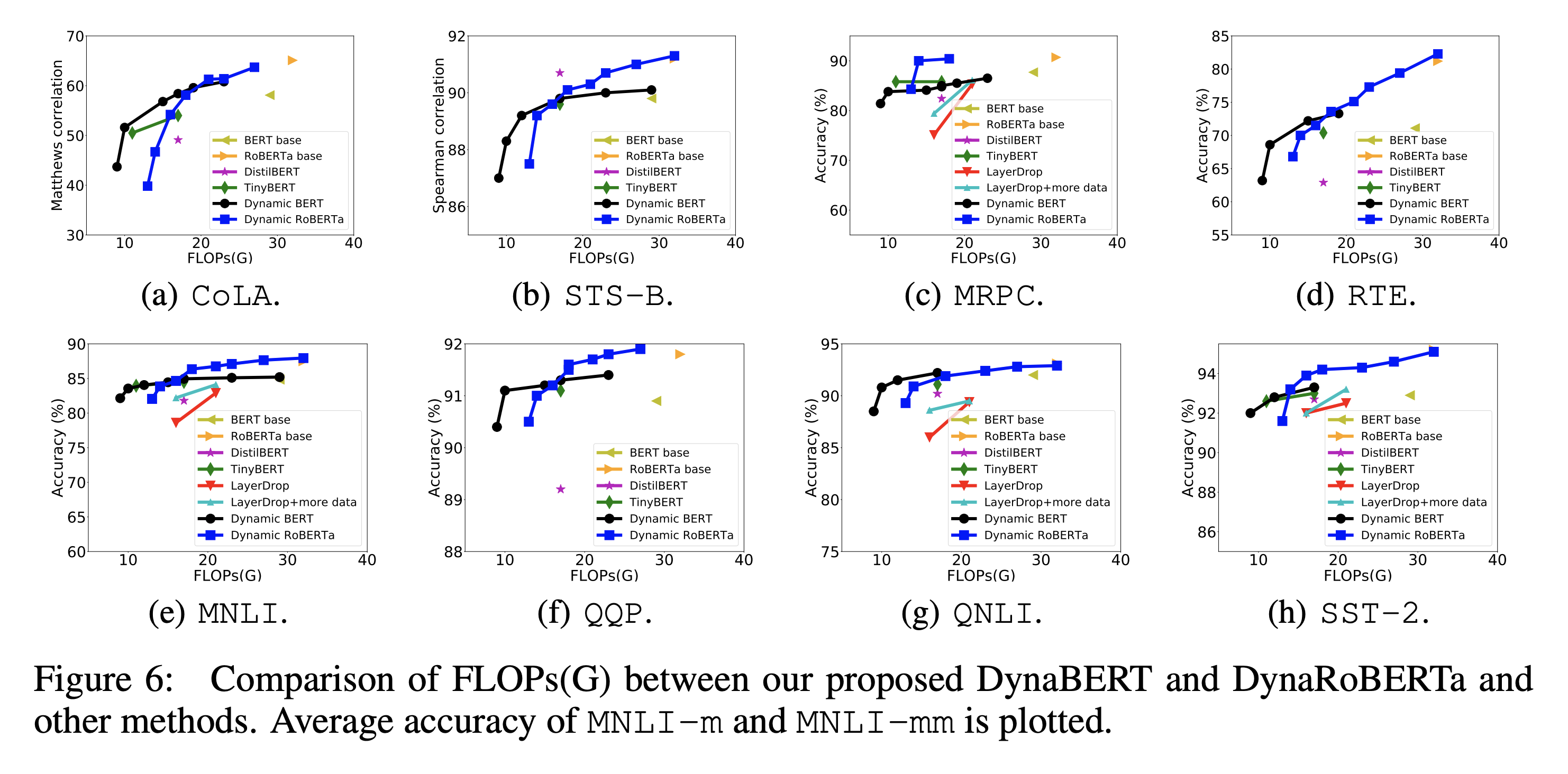
FLOPs와 정확도 사이의 비교 Plot
BERT Base와 RoBERTa Base와 계산 성능을 비교했을 때, 같은 수준의 Accuracy를 기록했음에도 불구하고 거의 2배 정도 연산을 적게 한 경우도 있음을 확인할 수 있습니다.
Ablation Study
Training DynaBERTW with Adaptive Width
Network Rewiring의 중요성을 알아보기 위해 이를 수행하지 않은 버전의 Vanilla DynaBERTW과 실제 모델을 비교 분석해보는 실험을 진행했습니다. 그 결과, Rewiring을 진행한 버전의 GLUE Benchmark Score가 그렇지 않은 버전의 2 point 이상을 웃돌았습니다. 여기에 Knowledge Distillation과 Data Augmentation을 더했더니 1.5 point 정도 더 상회했습니다.
Training DynaBERT with Adaptive Width and Depth
Knowledge Distillation, Data Augmentation, Final fine-tuning의 중요성을 알아보기 위해 4개의 GLUE Dataset(SST-2, CoLA, MRPC, RTE)에 대해 Vanilla DynaBERT와 실제 모델을 비교 분석해보는 실험을 진행했습니다.
그 결과 실제 모델이 모든 Dataset에 대해 확연히 차이나는 수준의 Performance를 보였습니다. Fine-tuning의 경우 대부분 Accuracy를 증가시켰으나 MRPC는 되려 감소시키는 효과를 보였습니다.
Discussion
Comparison of Conventional Distillation and Inplace Distillation
Width-adaptive CNN을 학습시킬 때 사용했던 Inplace Distillation을 DynaBERT에도 적용해보려는 시도가 있었습니다.
그 결과, MRPC와 CoLA에서는 Inplace Distillation을 사용한 DynaBERTW이 더 높은 Average Accuracy를 기록했습니다. 하지만 DynaBERT를 학습시킬 때는 되려 낮은 Performance를 기록했습니다.
Different Methods to Train DynaBERTW
Width-adaptive CNN에서 사용했던 몇 가지 Method들을 DynaBERTW에도 적용하려는 시도를 했습니다. 첫 번째는 Progressive Rewiring (큰 Width Mutiplier가 주어졌을 경우 Progressive하게 Rewiring)을 사용하는 것이고, 두 번째는 Universally Slimmable Training(Iteration마다 무작위로 Width Multiplier를 Sampling)을 적용하는 것입니다.
Progressive Rewiring의 경우 작업 자체가 시간을 소요하기 때문에 Data Augmentation이나 Distillation을 추가하지 않았습니다. 그 결과 별도로 눈에 띄는 수준의 성능 향상을 거두지 못했습니다.
Universally Slimmable Training의 경우 역시 Data Augmentation을 진행하지 않았는데, 역시 이전 실험 결과와 비교하여 큰 차이를 보이지 않았습니다.
Conclusion
Future Work로 Hidden State Size를 바꿔 Model을 더욱 압축시키고 추론 속도를 가속해보겠다고 합니다. Adaptive Depth에 대해서는 Trasnformer Layer들 사이에 Weight Sharing을 사용하는 것이 더 적합할 수도 있다는 가능성을 비쳤습니다.